Understanding GCP BigQuery Data Warehousing
What is Data Warehousing?
Data warehousing refers to the process of collecting, storing, and managing large volumes of data from various sources within an organization. The primary purpose of a data warehouse is to provide a centralized repository for structured and unstructured data, enabling businesses to make informed decisions based on comprehensive insights. It serves as a consolidated and optimized platform for efficient data analysis and reporting. In modern business analytics, data warehousing plays a crucial role in transforming raw data into valuable information, facilitating strategic decision-making processes.
The evolution of data warehousing has been closely tied to the advancements in technology and the increasing complexity of business data. Initially, businesses relied on traditional databases for data storage, but as the volume and variety of data grew, the limitations of these systems became apparent. Data warehousing emerged as a solution to these challenges, offering a more organized and efficient way to handle diverse datasets. In the contemporary business landscape, data warehousing is integral to extracting meaningful insights from the vast amounts of information generated daily.
The Need for Scalability
Traditional data warehousing faced significant challenges in handling the ever-growing volumes of data generated by organizations. As businesses expanded and the diversity of data types increased, conventional systems struggled to keep up with the demands for storage and processing power. This led to performance bottlenecks, slower query response times, and overall inefficiencies in data management.
Scalability addresses these challenges by providing the ability to seamlessly expand the data warehouse infrastructure as the volume of data grows. Scalable data warehouses can accommodate massive datasets, ensuring that the system remains responsive and performs optimally even as the organization’s data requirements evolve. This is particularly important in the context of modern data analytics, where real-time processing and analysis of large datasets are crucial for gaining timely insights.
Understanding data warehousing involves recognizing its role as a centralized repository for diverse data types and sources. The evolution of data warehousing reflects the need for more efficient and scalable solutions in the face of increasing data complexity. Scalability emerges as a key factor in addressing the challenges posed by traditional data warehousing, enabling organizations to harness the full potential of their data for informed decision-making in the dynamic landscape of modern business analytics.
Introduction to BigQuery
Overview
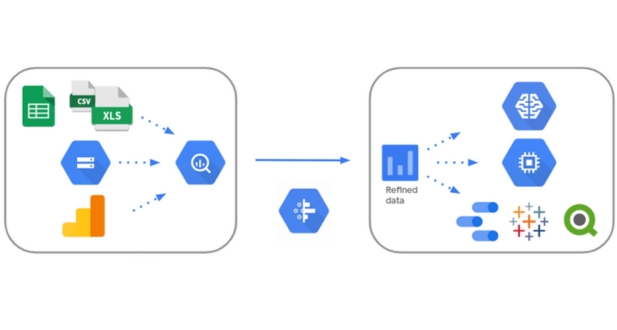
BigQuery is a powerful and fully-managed enterprise data warehouse solution offered by Google Cloud Platform. It has gained significant popularity in the field of big data analytics due to its scalability, speed, and ease of use. The development of BigQuery can be traced back to Google’s internal infrastructure for processing large datasets. Over time, Google recognized the potential of this technology in addressing broader industry needs and subsequently made it available as a cloud service.
Key features that distinguish BigQuery in the market include its serverless architecture, allowing users to focus on querying and analyzing data without the need for infrastructure management. BigQuery also boasts a pay-as-you-go pricing model, providing cost efficiency by charging users only for the resources they consume. Additionally, its integration with other Google Cloud services and third-party tools makes it a versatile and comprehensive solution for handling diverse data analytics requirements.
Core Components
At the heart of BigQuery’s architecture is its distributed computing infrastructure, designed to process and analyze massive datasets with impressive speed. The architecture is built on Google’s Dremel technology, which enables interactive and real-time querying of large datasets. Understanding the core components of BigQuery is crucial for users to harness its capabilities effectively.
Datasets in BigQuery serve as logical containers for organizing and controlling access to tables. They allow users to group related tables together, making it easier to manage and secure data. Tables, on the other hand, store the actual data and are organized into rows and columns. BigQuery supports various data formats, including CSV, JSON, and Parquet, providing flexibility in handling diverse types of data.
Queries are at the forefront of BigQuery’s functionality, allowing users to retrieve, analyze, and manipulate data. The SQL-like syntax makes it accessible to users familiar with standard database query languages, simplifying the learning curve for those transitioning from traditional database systems. The ability to run complex queries on large datasets swiftly is a hallmark feature of BigQuery, making it a preferred choice for organizations dealing with substantial amounts of data.
BigQuery stands out in the market as a robust and user-friendly solution for big data analytics. Its history rooted in Google’s internal infrastructure, coupled with distinctive features like serverless architecture and seamless integration, positions it as a leading choice for organizations seeking efficient and scalable data processing and analysis. Understanding its core components, including datasets, tables, and queries, is essential for users to leverage BigQuery effectively in their data analytics workflows.
Key Features of BigQuery

Serverless Data Warehousing: Eliminating the Need for Infrastructure Management
One of the key features of BigQuery is its serverless data warehousing capability. This means that users are relieved of the burdensome task of managing infrastructure. Unlike traditional data warehouses that require careful planning, provisioning, and scaling of servers, BigQuery operates in a serverless environment. This results in significant cost-effectiveness and ease of use for businesses, as they no longer need to allocate resources and time to manage the underlying infrastructure. Users can focus more on extracting insights from their data rather than worrying about the complexities of infrastructure management.
Real-time Data Analysis: Streaming Data into BigQuery
BigQuery supports real-time data analysis by allowing users to stream data directly into the platform. This feature is particularly crucial in today’s fast-paced business environment, where timely insights can make a significant impact. By enabling the ingestion of streaming data, BigQuery facilitates the analysis of data as it arrives, providing organizations with the ability to derive instant insights. This real-time capability is invaluable for applications such as monitoring, fraud detection, and other scenarios where up-to-the-minute information is critical for decision-making.
Federated Queries: Accessing and Analyzing Data Across Multiple Sources
BigQuery offers federated queries, allowing users to access and analyze data from multiple sources seamlessly. This feature is instrumental in achieving a unified view of diverse datasets scattered across various platforms and locations. Instead of having data silos that hinder comprehensive analysis, federated queries enable businesses to pull together information from different databases, cloud platforms, and on-premises systems. This capability enhances the overall efficiency of data analysis and reporting by providing a consolidated and holistic perspective, essential for informed decision-making in complex and data-rich environments.
BigQuery’s Integration with GCP

Integration with Google Cloud Storage
BigQuery’s integration with Google Cloud Storage (GCS) is a pivotal aspect of its functionality. Google Cloud Storage serves as a robust and scalable solution for storing and managing large datasets. This integration allows users to seamlessly store and access their vast datasets in Cloud Storage directly from BigQuery, fostering a cohesive environment for data management. The synergy between BigQuery and Cloud Storage ensures that users can efficiently leverage the benefits of both platforms, capitalizing on the storage capabilities of Cloud Storage and the analytical prowess of BigQuery.
The seamless interaction between BigQuery and Cloud Storage extends beyond mere storage convenience. It enables users to perform complex analytics and queries on the data stored in Cloud Storage, without the need for cumbersome data transfers. This integration is particularly advantageous for organizations dealing with massive datasets, as it streamlines data workflows and minimizes latency associated with data movement.
Machine Learning Integration
One of the standout features of BigQuery is its integration with machine learning capabilities. By seamlessly incorporating machine learning within the BigQuery environment, users can unlock powerful tools for predictive analytics and decision-making. This integration enhances the platform’s versatility, allowing users to go beyond traditional data analysis and delve into the realm of predictive modeling.
The machine learning integration within BigQuery empowers users to build and deploy machine learning models directly on their datasets. This functionality is invaluable for organizations seeking to extract deeper insights and make data-driven decisions. By leveraging machine learning algorithms within BigQuery, users can uncover patterns, trends, and correlations in their data, ultimately enhancing the accuracy and efficacy of predictive analytics.
Moreover, the integration facilitates a streamlined workflow, eliminating the need for data movement between different platforms for machine learning tasks. This not only enhances efficiency but also ensures that the analytical and machine learning components work seamlessly together, creating a unified environment for comprehensive data analysis. Overall, the machine learning integration in BigQuery adds a layer of sophistication to data analytics, making it a versatile and powerful tool for organizations looking to harness the full potential of their data.
Performance and Optimization
Automatic Query Optimization:
BigQuery, Google’s fully-managed serverless data warehouse, employs automatic query optimization techniques to enhance performance and ensure efficient data processing. This optimization is crucial for handling large-scale datasets and complex queries. BigQuery’s query execution engine automatically analyzes the structure of queries and optimizes their execution plans. This involves choosing the most efficient method for accessing and processing data, such as selecting appropriate join algorithms, optimizing filtering conditions, and minimizing data movement.
One key aspect of automatic query optimization in BigQuery is its utilization of caching mechanisms. Caching involves storing the results of previously executed queries so that if the same or similar query is issued again, the system can retrieve the results from the cache rather than re-executing the entire query. This significantly speeds up repetitive queries, reducing the overall processing time and enhancing the user experience. Caching is particularly effective for queries that involve static or slowly changing data.
Partitioning and Clustering:
In the realm of organizing data within BigQuery, partitioning and clustering are essential strategies aimed at maximizing efficiency and optimizing query performance.
- Partitioning: BigQuery allows users to partition tables based on a specified column, typically a date or timestamp. This means that the table’s data is physically organized into smaller, more manageable segments based on the chosen partition key. When queries involve conditions that align with the partition key, the system can eliminate irrelevant partitions from the scan, reducing the amount of data that needs to be processed. This results in faster query performance, especially for date-range queries where only a subset of the data is relevant.
- Clustering: In addition to partitioning, BigQuery supports clustering, which involves organizing the data within each partition based on another column or set of columns. This helps in further narrowing down the data that needs to be scanned during query execution. Clustering is especially beneficial when there are common patterns in the data, as it can significantly reduce the amount of data that needs to be processed to fulfill a query. Well-chosen clustering keys can lead to substantial improvements in query performance by facilitating more efficient data retrieval.
Security and Compliance:
In the realm of information technology, maintaining robust security measures is paramount to safeguarding sensitive data and ensuring compliance with industry standards. Two key components that play a pivotal role in this regard are data encryption and access control with auditing.
Data Encryption :
Data encryption is a fundamental aspect of securing information. It involves converting plain-text data into a coded format, making it indecipherable without the appropriate decryption key. Encryption operates in two critical states: in transit and at rest. Encrypting data in transit ensures the protection of information as it traverses networks, preventing unauthorized interception and tampering. Simultaneously, encrypting data at rest involves securing information stored on physical or digital storage mediums, safeguarding it from unauthorized access even if the storage device is compromised.
Ensuring robust data encryption is essential for safeguarding sensitive information from potential breaches and unauthorized access, thus forming a cornerstone of any comprehensive security strategy.
Access Control and Auditing :
Access control and auditing are integral components of managing data security, focusing on regulating user permissions and monitoring data access for accountability.
- Access Control:
Access control involves the implementation of mechanisms that restrict user access to specific resources based on predefined permissions. This ensures that only authorized personnel can access sensitive information, mitigating the risk of unauthorized data manipulation or exposure. By employing access control measures, organizations can tailor user privileges according to their roles, enforcing the principle of least privilege and reducing the attack surface.
- Auditing:
Auditing complements access control by providing a systematic way to monitor and record data access activities. Through detailed logs and reports, organizations can track who accessed what data, when, and for what purpose. This not only aids in detecting potential security breaches but also serves as a valuable tool for compliance audits. Auditing contributes to transparency, accountability, and the ability to investigate security incidents promptly.
Use Cases and Success Stories

BigQuery, a powerful and scalable cloud-based data warehouse offered by Google Cloud, finds widespread application across diverse industries, showcasing its versatility and impact on data analytics. In the realm of industry applications, BigQuery plays a pivotal role in transforming raw data into actionable insights, thereby empowering decision-makers. The following paragraphs delve into the use cases and success stories across various sectors.
Industry Applications:
BigQuery’s application extends across industries such as finance, healthcare, retail, manufacturing, and more. In finance, organizations leverage BigQuery to analyze vast amounts of financial data in real-time, facilitating faster and more informed decision-making. Healthcare institutions utilize BigQuery to derive meaningful insights from patient records, optimizing treatment plans and improving overall patient care. In the retail sector, businesses harness the power of BigQuery to analyze customer behavior, optimize inventory management, and enhance the overall customer experience. The manufacturing industry benefits from BigQuery by streamlining supply chain operations, improving efficiency, and reducing costs through data-driven insights.
Case Studies:
Numerous case studies highlight the successful implementation of BigQuery in solving complex business challenges. For instance, a leading financial institution utilized BigQuery to analyze transaction data in real-time, identifying potential fraudulent activities and enhancing security measures. In healthcare, a hospital system employed BigQuery to analyze patient data, leading to the development of personalized treatment plans and improved patient outcomes. Retail giants have leveraged BigQuery to analyze customer preferences and behaviors, enabling targeted marketing strategies and increasing customer satisfaction.
Success Stories:
BigQuery’s success stories underscore its positive impact on organizations’ operational efficiency and strategic decision-making. A notable success story involves a global e-commerce platform that utilized BigQuery to analyze user behavior, leading to personalized recommendations and a significant increase in sales. Another success story revolves around a manufacturing company that implemented BigQuery to optimize its supply chain, resulting in reduced lead times and improved production efficiency. These success stories demonstrate how BigQuery transcends industry boundaries, delivering tangible benefits to organizations across the spectrum.
BigQuery’s industry applications are diverse and far-reaching, with case studies and success stories serving as compelling evidence of its transformative capabilities. As businesses continue to grapple with an ever-increasing volume of data, BigQuery stands out as a robust solution, enabling them to extract valuable insights and stay ahead in an increasingly data-driven world.
Challenges and Considerations in Data Warehousing
Addressing Common Challenges
In the realm of data warehousing, organizations often grapple with common challenges that demand strategic solutions. One such challenge is the management of large and complex datasets. As businesses accumulate vast amounts of data from various sources, the task of handling this information efficiently becomes paramount. This involves developing robust infrastructure and employing advanced data management techniques to ensure the smooth processing and retrieval of relevant information.
Another pressing concern is managing costs and optimizing resource utilization. Data warehousing initiatives can incur substantial expenses, both in terms of infrastructure and ongoing operational costs. Organizations must strike a delicate balance between providing the necessary resources for efficient data processing and ensuring cost-effectiveness. This involves implementing cost management strategies, utilizing cloud-based solutions judiciously, and adopting optimization techniques to streamline resource usage.
Planning for Growth
As businesses evolve, so do their data requirements. Planning for growth is a crucial aspect of data warehousing strategies. Scalability considerations play a pivotal role in ensuring that the infrastructure can seamlessly adapt to the evolving business needs. Organizations need to anticipate future data volumes and user demands to design scalable architectures that can expand without compromising performance. This may involve adopting distributed computing frameworks, horizontal scaling, or cloud-based solutions to accommodate growing datasets.
Future-proofing data warehousing strategies is another key consideration in the planning phase. Given the rapid pace of technological advancements, it’s essential to adopt solutions that can withstand the test of time. This includes selecting flexible and adaptable technologies, staying abreast of emerging trends, and building a framework that can incorporate new functionalities as they become available. By future-proofing their data warehousing strategies, organizations can ensure that their systems remain relevant and effective in the face of evolving technologies and business landscapes.
Yes, BigQuery is suitable for real-time analytics due to its ability to handle large datasets and provide low-latency query results.
BigQuery uses a pay-as-you-go pricing model, where you are charged based on the amount of data processed by your queries.
Yes, you can load data into BigQuery from various external sources, including Cloud Storage, Cloud SQL, and other Google Cloud services.
BigQuery supports various data formats, including CSV, JSON, Avro, Parquet, and ORC.
BigQuery supports very large datasets, and there is no maximum limit on the size of datasets.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}