

Introduction to AWS Disaster Recovery Solutions
In today’s dynamic business landscape, the ability to swiftly recover from unforeseen disasters is integral to sustaining operations and safeguarding data integrity. This is where Disaster Recovery (DR) solutions come into play, and AWS stands at the forefront as a robust platform for implementing such critical strategies.
Overview of Disaster Recovery (DR)
- Disaster Recovery Defined:
Disaster Recovery is a proactive approach aimed at minimizing the impact of unplanned events, such as natural disasters, cyber-attacks, or system failures, on an organization’s operations. The essence of DR lies in the ability to swiftly resume normal business functions with minimal downtime and data loss.
- Importance of Disaster Recovery:
Ensuring Business Continuity: DR goes beyond mere data backup; it encompasses comprehensive strategies to guarantee the continuous operation of essential services and processes, irrespective of external disruptions. The goal is to fortify an organization’s resilience against potential threats.
AWS as a Disaster Recovery Solution
- The AWS Advantage:
Amazon Web Services (AWS) emerges as a beacon of reliability in the realm of Disaster Recovery. Renowned for its global infrastructure, AWS provides a comprehensive suite of services that empower organizations to design and implement resilient DR solutions tailored to their unique needs.
Key Features of AWS for Disaster Recovery:
- Global Reach: AWS operates across multiple geographic regions, offering organizations the flexibility to establish disaster recovery sites in diverse locations, ensuring redundancy and minimizing regional risks.
- Scalability: AWS’s cloud infrastructure allows for seamless scalability, enabling organizations to adjust resources based on evolving DR requirements without the need for significant upfront investments.
- Automated Backup Services: Leveraging services like Amazon S3 and AWS Backup, organizations can automate the backup and recovery of critical data, ensuring its accessibility in the event of a disaster.
- High Availability Architectures: AWS supports the deployment of applications across multiple Availability Zones (AZs), enhancing availability and reducing the risk of single points of failure.
Cost-Efficiency and Pay-as-You-Go Model:
AWS follows a cost-efficient pay-as-you-go pricing model, enabling organizations to optimize DR costs by paying only for the resources they consume during normal operations and scaling up during recovery scenarios.
- Real-world Success Stories:
Numerous organizations across industries have successfully implemented AWS Disaster Recovery solutions, showcasing the platform’s efficacy in mitigating risks and ensuring operational resilience. These success stories stand as testaments to AWS’s role as a trusted ally in the face of adversity.
In conclusion, the introduction of AWS Disaster Recovery Solutions sets the stage for a deeper exploration of the features, strategies, and real-world applications that make AWS a go-to platform for organizations striving to fortify their business continuity efforts.

Understanding Disaster Recovery Planning
Disaster Recovery (DR) planning is the cornerstone of a resilient business strategy. This section delves into the meticulous process of assessing risks, vulnerabilities, and setting recovery objectives to fortify organizations against potential disruptions.
Assessment of Risks and Vulnerabilities
- Identifying Potential Threats:
The first step in effective disaster recovery planning is conducting a thorough assessment of risks and vulnerabilities. This involves identifying potential threats that could jeopardize business continuity. These threats span a wide spectrum, encompassing natural disasters like earthquakes and floods, cyber threats such as ransomware attacks, and operational risks like equipment failures.
- Impact Analysis:
For each identified threat, a comprehensive impact analysis is crucial. Understanding how each threat could affect business operations, data integrity, and overall infrastructure is paramount. This analysis informs the prioritization of recovery efforts, ensuring that critical systems and processes receive the necessary attention.
- Technological and Environmental Considerations:
Organizations need to evaluate their technological landscape and environmental factors that might contribute to vulnerabilities. This includes assessing the robustness of data centers, the security of networks, and the adaptability of existing systems to potential disruptions.
Defining Recovery Objectives
- Establishing Recovery Time Objectives (RTO):
RTO defines the acceptable duration for restoring systems and applications to normal functionality after a disruptive event. It represents the maximum tolerable downtime for specific processes. For instance, critical customer-facing applications might have a shorter RTO compared to internal support systems.
- Setting Recovery Point Objectives (RPO):
RPO determines the allowable data loss in the event of a disruption. It signifies the point in time to which data must be recovered to resume normal operations. Organizations must align RPO with business processes, ensuring that critical data is backed up frequently to minimize potential data loss.
- Prioritizing Applications and Systems:
Not all applications and systems hold equal importance for business operations. Disaster recovery planning involves categorizing and prioritizing applications based on their criticality. High-priority systems with short RTOs and low RPOs demand more robust recovery strategies.
- Consideration of Dependencies:
Organizations operate in an interconnected environment where the functionality of one system often depends on others. Disaster recovery planning should account for these dependencies, ensuring that interconnected systems are recovered in a synchronized manner to maintain coherence.
- Continuous Review and Adaptation:
As technology evolves and organizational landscapes change, it’s imperative to continuously review and adapt disaster recovery plans. Regular assessments ensure that plans remain aligned with current risks, technologies, and business priorities.
In conclusion, understanding disaster recovery planning involves a meticulous examination of risks, vulnerabilities, and the establishment of recovery objectives. This foundational knowledge forms the basis for crafting robust strategies that can withstand the diverse array of threats that businesses face in today’s dynamic environment.
AWS Disaster Recovery Services Overview

Amazon Web Services (AWS) offers a robust suite of disaster recovery services that empower organizations to safeguard their data, ensure business continuity, and recover swiftly from disruptions. In this section, we explore key AWS Disaster Recovery Services, including Amazon S3, Amazon Glacier, and AWS Backup, unraveling their functionalities and applications in the realm of disaster recovery.
Amazon S3 (Simple Storage Service)
- Utilizing S3 for Data Backup:
Amazon S3 stands as a cornerstone in AWS’s disaster recovery arsenal. Renowned for its scalability, durability, and versatility, S3 serves as a robust platform for data backup. Organizations can leverage S3 to securely store and retrieve any amount of data, ensuring that critical information is protected against loss or corruption.
- Storage Redundancy for Resilience:
One of the key features of S3 is its ability to provide redundancy through multiple Availability Zones (AZs). This ensures that data remains accessible even if one AZ faces a disruption. By configuring data replication across different AZs, organizations enhance the resilience of their disaster recovery strategies.
Amazon Glacier
- Leveraging Glacier for Long-term Data Archival:
Amazon Glacier complements S3 by offering a cost-effective solution for long-term data archival. Designed for infrequently accessed data, Glacier enables organizations to archive data for extended periods while keeping costs low. This service is particularly useful for storing data that may not require frequent retrieval but is crucial for compliance or historical purposes.
- Cost-Effective Storage Solution:
Glacier operates on a pricing model that aligns with its archival nature, making it a cost-effective choice for organizations seeking to balance storage expenses with data preservation needs. It provides a secure and durable option for maintaining data integrity over extended periods.
AWS Backup
- Exploring AWS Backup as a Centralized Solution:
AWS Backup streamlines the backup and recovery processes by offering a centralized solution for managing backups across various AWS services. It provides a unified interface to configure and monitor backups, ensuring a consistent and efficient approach to disaster recovery.
Key Features of AWS Backup:
- Application Consistency: AWS Backup ensures application-consistent backups, critical for recovering complex systems without data inconsistencies.
- Automated Backup Policies: Organizations can define automated backup policies, simplifying the management of backup schedules and retention periods.
- Cross-Service Backup: AWS Backup supports a wide range of AWS services, allowing organizations to create a comprehensive backup strategy covering diverse resources.
In conclusion, this overview of AWS Disaster Recovery Services highlights the versatility and efficiency of Amazon S3, Amazon Glacier, and AWS Backup. These services form a robust foundation for organizations seeking resilient disaster recovery solutions within the AWS ecosystem.
Disaster Recovery Strategies with AWS

In the unpredictable landscape of IT, crafting effective disaster recovery strategies is paramount for ensuring business resilience and continuity. Amazon Web Services (AWS) offers versatile approaches that empower organizations to tailor their disaster recovery plans to specific needs. In this section, we explore key disaster recovery strategies provided by AWS, including Backup and Restore, the Pilot Light Approach, and the Warm Standby model.
Backup and Restore
- Implementing Regular Backups:
The cornerstone of any disaster recovery strategy is the systematic backup and restoration of critical data and systems. AWS facilitates this through its robust backup and restore capabilities. Organizations can establish routine backup schedules, creating duplicate copies of vital data. In the event of data loss or system failure, the restoration process is expedited, minimizing downtime and potential losses.
AWS Services for Backup:
- Amazon S3: Leverage S3 for scalable and secure data backup.
- AWS Backup: Utilize AWS Backup for centralized management of backup policies across various AWS services.
- Amazon RDS Backup: Implement automated backups for Amazon RDS databases to ensure data consistency.
Pilot Light Approach
- Essential Infrastructure Components Ready to Ignite:
The Pilot Light Approach involves maintaining essential components in AWS, ready to be swiftly scaled up in case of a disaster. This approach is akin to having a pilot light continuously burning, allowing organizations to quickly ignite a fully functional environment when needed.
Key Features:
- Cost Efficiency: By keeping only essential components active, organizations optimize costs while ensuring a rapid response during a disaster.
- Scalability: The infrastructure components in the Pilot Light Approach can be scaled up efficiently, adapting to the organization’s needs in the event of a disaster.
Warm Standby
- Reducing Recovery Time with a Partially Active Environment:
In the Warm Standby model, organizations maintain a partially active environment in AWS. While not fully operational, critical components are kept running, reducing recovery time compared to a cold standby approach.
Benefits of Warm Standby:
- Faster Recovery: With essential components already running, the transition to a fully operational state is faster compared to starting from scratch.
- Balanced Cost and Performance: Warm Standby strikes a balance between the cost efficiency of cold standby and the faster recovery of hot standby.
Choosing the Right Strategy
Selecting the most suitable disaster recovery strategy depends on factors such as recovery time objectives (RTO), recovery point objectives (RPO), and budget constraints. Organizations may even employ a combination of these strategies for comprehensive disaster preparedness.
High Availability Architectures on AWS
Ensuring high availability is a critical aspect of disaster recovery planning, and Amazon Web Services (AWS) provides a robust set of tools and services to build resilient architectures. In this section, we explore high availability architectures on AWS, focusing on Multi-AZ Deployment, Amazon Route 53, and AWS Auto Scaling.
Multi-AZ Deployment
- Automatic Failover Across Availability Zones:
A Multi-AZ (Availability Zone) deployment involves distributing applications across multiple data centers, ensuring redundancy and automatic failover in case of a disruption in one zone. AWS customers can leverage this architecture to enhance fault tolerance and maintain continuous availability.
Key Features:
- Redundancy: By deploying identical resources in different Availability Zones, organizations minimize the risk of a single point of failure.
- Automatic Failover: In the event of a failure in one zone, traffic is seamlessly redirected to healthy instances in another, ensuring uninterrupted service.
Amazon Route 53
- DNS Failover for Seamless Traffic Rerouting:
Amazon Route 53, AWS’s scalable and highly available domain name system (DNS) web service, plays a pivotal role in high availability architectures. It facilitates DNS failover, automatically redirecting traffic to healthy endpoints in case of a service disruption.
Benefits of Route 53:
- Global Anycast Routing: Route 53 leverages global Anycast routing, directing users to the nearest healthy endpoint, enhancing performance and reducing latency.
- Health Checks: Constant monitoring of endpoint health allows Route 53 to intelligently reroute traffic, ensuring optimal user experience.
AWS Auto Scaling
- Dynamic Scaling for Performance and Availability:
AWS Auto Scaling empowers organizations to maintain optimal performance and availability by dynamically adjusting the number of instances in response to demand fluctuations. This ensures that the application can efficiently handle varying workloads.
Key Advantages:
- Cost Efficiency: Auto Scaling helps optimize costs by automatically adjusting resources based on actual demand, preventing overprovisioning.
- Enhanced Fault Tolerance: In addition to scaling based on demand, Auto Scaling can replace unhealthy instances, further bolstering the overall fault tolerance of the architecture.
Achieving Comprehensive High Availability
By strategically combining Multi-AZ Deployment, Amazon Route 53, and AWS Auto Scaling, organizations can construct a comprehensive high availability architecture on AWS. This not only safeguards against potential failures but also provides a scalable and efficient infrastructure capable of meeting the demands of dynamic workloads.
In the upcoming sections, we will explore best practices for implementing these high availability strategies, examine real-world scenarios, and offer insights to guide organizations in fortifying their AWS disaster recovery solutions.
Testing and Maintenance of Disaster Recovery Plans
Ensuring the reliability and effectiveness of disaster recovery plans is a continuous process that involves regular testing and meticulous maintenance. In this section, we delve into the crucial aspects of testing and maintaining disaster recovery plans on AWS.
Regular Testing Exercises
- Simulated Disaster Scenarios:
Regular testing is fundamental to disaster recovery preparedness. Organizations should conduct simulated disaster scenarios, ranging from system failures to complete data center outages, to validate the efficiency and effectiveness of their recovery plans. These exercises help identify weaknesses, refine procedures, and ensure teams are well-prepared to respond swiftly during an actual crisis.
Key Considerations:
Scenario Diversity: Testing should encompass various disaster scenarios to evaluate the adaptability and responsiveness of recovery plans.
Involvement of Stakeholders: Engaging stakeholders in testing exercises ensures a comprehensive evaluation of the entire recovery process.
Continuous Monitoring
- Proactive Detection and Mitigation:
Continuous monitoring of AWS resources and performance metrics is imperative for proactively detecting potential issues that could disrupt operations. By leveraging AWS monitoring tools, organizations can identify anomalies, assess the health of their infrastructure, and swiftly implement corrective measures.
- Monitoring Best Practices:
Utilizing AWS CloudWatch: AWS CloudWatch provides real-time monitoring and automated responses to changes in performance, ensuring proactive issue resolution.
Customized Alerts and Notifications: Configuring customized alerts and notifications allows teams to stay informed about potential disruptions and respond promptly.
Ensuring Resilience through Testing and Monitoring
Regular testing exercises and continuous monitoring form the bedrock of a resilient disaster recovery strategy on AWS. By incorporating these practices into their routine operations, organizations can enhance their ability to withstand unforeseen events, minimize downtime, and maintain the integrity of their critical systems and data.
Cost Considerations and Optimization
Managing costs is a pivotal aspect of disaster recovery planning on AWS, ensuring organizations can effectively balance resilience with financial efficiency. In this section, we explore key cost considerations and optimization strategies for achieving a balance between cost-effectiveness and robust disaster recovery solutions.
Cost-Efficient Storage Solutions
- Strategic Storage Selection:
Selecting the appropriate storage solutions based on cost and performance requirements is critical for optimizing expenses. AWS offers a range of storage options, each with its own pricing structure and performance characteristics. Organizations must evaluate their data access patterns and choose storage classes that align with their budget constraints while meeting recovery time objectives (RTO) and recovery point objectives (RPO).
- Optimizing Storage Costs:
- Data Lifecycle Management: Implementing data lifecycle management strategies helps organizations automatically transition data to cost-effective storage classes based on access frequency.
- Understanding Storage Tiers: Leveraging the right combination of storage classes, such as Amazon S3 Standard, S3 Intelligent-Tiering, and Glacier, ensures a balance between performance and cost efficiency.
Reserved Instances
- Predictable Workload Optimization:
For workloads with predictable usage patterns, reserved instances offer a cost-effective option. By committing to a one- or three-year term, organizations benefit from significant cost savings compared to on-demand instances. Reserved instances are particularly advantageous for steady-state applications that maintain consistent resource requirements.
Key Advantages:
- Cost Predictability: Reserved instances provide cost predictability, enabling organizations to plan their budgets more effectively.
- Long-Term Savings: The longer the commitment period, the greater the cost savings, making reserved instances a strategic choice for stable workloads.
Achieving Cost-Efficiency Without Compromising Resilience
Balancing cost considerations with the need for a resilient disaster recovery solution is essential. By strategically selecting storage solutions and leveraging reserved instances, organizations can optimize costs without compromising their ability to recover swiftly from disruptions.
Compliance and Security in Disaster Recovery
In the realm of disaster recovery on AWS, safeguarding data integrity and adhering to stringent compliance standards are paramount. This section delves into the crucial components of data security and compliance, ensuring that disaster recovery solutions on AWS align with the highest standards of protection.
Data Encryption
- Holistic Security Measures:
Implementing robust data encryption practices is fundamental to fortifying disaster recovery solutions. Encryption serves as a comprehensive safeguard, protecting data both in transit and at rest. Leveraging encryption mechanisms ensures that sensitive information remains confidential, mitigating the risk of unauthorized access or data breaches during recovery operations.
- Encryption Best Practices:
In Transit: Utilizing secure communication protocols, such as TLS/SSL, to encrypt data during transit.
At Rest: Employing AWS Key Management Service (KMS) to manage and control access to encryption keys, securing data stored in various AWS services.
Compliance Standards
- Adherence to Industry Regulations:
Meeting industry regulations and compliance standards is non-negotiable for organizations safeguarding critical data. Disaster recovery solutions on AWS must align with frameworks like HIPAA, GDPR, and other regional or industry-specific mandates. Compliance ensures that data protection measures are in line with recognized standards, fostering trust and regulatory adherence.
Compliance Best Practices:
- Regulatory Assessments: Regularly assessing disaster recovery processes to ensure ongoing compliance with evolving regulations.
- Documentation and Auditing: Maintaining comprehensive documentation and conducting regular audits to validate compliance adherence.
Fortifying Disaster Recovery with Security and Compliance
By intertwining robust data encryption practices and strict adherence to compliance standards, organizations fortify their disaster recovery solutions on AWS. This not only mitigates risks associated with data breaches but also establishes a foundation of trust with stakeholders and regulatory bodies.
Case Studies: Successful Implementations of AWS Disaster Recovery
Unveiling the Real-World Triumphs
Embark on a journey through real-world success stories that showcase the resilience and effectiveness of AWS disaster recovery solutions. These case studies illuminate how organizations navigated challenges, implemented robust strategies, and emerged stronger in the face of unforeseen disruptions.
Real-World Examples
- Diverse Industry Insights:
Explore case studies spanning diverse industries, from healthcare to finance, unveiling how AWS disaster recovery solutions tailored to specific needs can be instrumental in mitigating risks and ensuring seamless business continuity.
Lessons Learned
- Invaluable Insights for Strategy Refinement:
Delve into the lessons learned from these real-world scenarios. Extract actionable insights and best practices that can enhance disaster recovery strategies, offering a roadmap for organizations seeking to fortify their resilience in the ever-evolving landscape.
Future Trends in AWS Disaster Recovery

Anticipating Tomorrow’s Resilience
As technology evolves, so does the landscape of disaster recovery on AWS. In this section, we set our sights on the horizon, exploring the imminent advancements and trends that promise to redefine how organizations approach and implement disaster recovery strategies.
Advancements in Cloud Technology
- Innovative Solutions on the Horizon:
Uncover the cutting-edge technologies that are poised to shape the future of AWS disaster recovery. From enhanced automation capabilities to the integration of artificial intelligence and machine learning, anticipate a landscape where recovery processes become more proactive, efficient, and seamlessly integrated into the broader cloud ecosystem.
Conclusion
In the ever-changing landscape of modern business, the ability to recover swiftly and seamlessly from disruptions is non-negotiable. AWS Disaster Recovery Solutions emerge as a beacon of resilience, offering organizations a robust framework to safeguard their operations against unforeseen challenges.
As we conclude this comprehensive exploration, it is evident that AWS provides not just a platform but a strategic ally in fortifying business continuity. From the meticulous planning stages to the execution of diverse recovery strategies, AWS empowers organizations to navigate disruptions with confidence.
The journey through disaster recovery planning, implementation, and optimization is a testament to the dynamic capabilities of AWS services. By embracing high availability architectures, testing methodologies, and aligning with stringent security and compliance standards, organizations can fortify their defenses against a spectrum of potential threats.
The case studies shared underscore the real-world triumphs, offering invaluable insights for organizations embarking on their disaster recovery journey. Looking ahead, the future trends in AWS Disaster Recovery hint at a landscape where technology continues to evolve, presenting innovative solutions that will redefine how organizations ensure resilience in the face of adversity.
In the spirit of continuous improvement, organizations are encouraged to not only embrace the current state-of-the-art but also remain agile, anticipating and adapting to the future trends that will shape the realm of AWS Disaster Recovery. Through collaboration, innovation, and a commitment to proactive planning, organizations can confidently stride into the future, knowing that AWS stands as a steadfast partner in their quest for uninterrupted business continuity.
AWS Disaster Recovery refers to the set of strategies and services provided by Amazon Web Services to help organizations prepare for and recover from potential disasters, ensuring the continuity of their operations.
Disaster recovery on AWS is crucial for maintaining business continuity. It safeguards data, applications, and infrastructure, ensuring that organizations can swiftly recover from disruptions caused by natural disasters, system failures, or cyberattacks.
Key AWS services for disaster recovery include Amazon S3 for data storage, Amazon Glacier for long-term archival, AWS Backup for centralized backup management, and high-availability architectures using Multi-AZ deployment.
AWS ensures data security through robust encryption practices, both in transit and at rest. Compliance with industry regulations, access controls, and continuous monitoring further enhance the security posture.
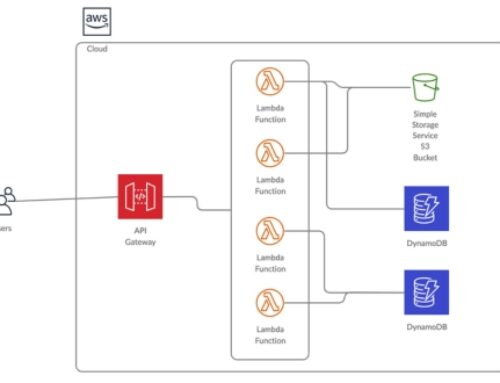
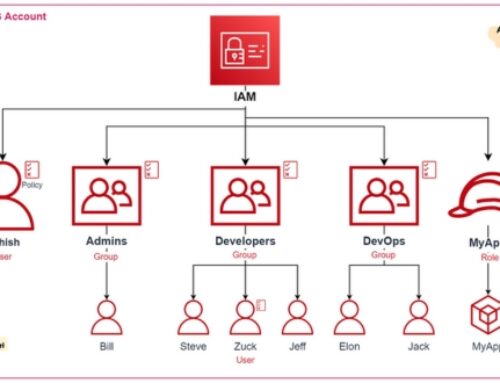


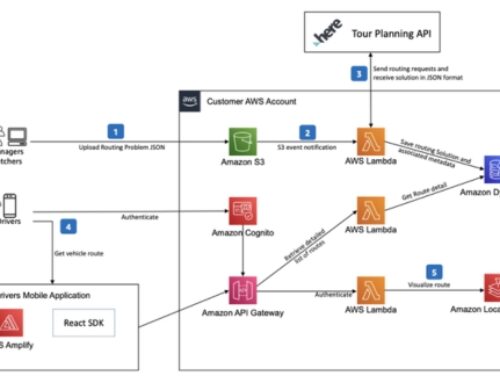


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}