Introduction
Cross-region data replication is a critical component within the AWS (Amazon Web Services) architecture, facilitating the duplication of data across different geographical regions. This process ensures data redundancy, high availability, disaster recovery preparedness, and improved AWS service and application performance.
Definition of Cross-Region Data Replication
Cross-region data replication involves the synchronization of data across multiple AWS regions. In this context, a region refers to a geographical area where AWS maintains data centres. Each region consists of multiple availability zones, distinct locations engineered to be isolated from failures in other zones within the same region.
Data replication across regions can occur in various ways, including:
Synchronous Replication: In this mode, data is replicated instantaneously across regions, ensuring consistency between the primary and replica data. However, synchronous replication might introduce latency due to the requirement of acknowledgment from the replica region before completing write operations.
Asynchronous Replication: Asynchronous replication allows for a more flexible approach, where data is replicated with a delay between regions. This approach can result in potential data inconsistencies but provides better performance and scalability, especially for applications with high write-throughput.
Importance in AWS Architecture
High Availability: By replicating data across multiple regions, AWS ensures that services remain available even in the event of a regional outage or failure. Users can access resources from the nearest available region, minimizing downtime and maintaining service continuity.
Disaster Recovery: Data replication enables organizations to implement robust disaster recovery strategies. In the event of a catastrophic failure in one region, data stored in other regions can be leveraged for recovery purposes, ensuring business continuity and minimizing data loss.
Compliance and Data Sovereignty: Cross-region replication allows organizations to adhere to regulatory requirements regarding data residency and sovereignty. By replicating data in specific regions, businesses can ensure compliance with data protection laws and regulations governing the storage and processing of sensitive information.
Improved Performance: Replicating data closer to end-users reduces latency and enhances the overall performance of applications and services. Users experience faster response times and improved data access, leading to a better overall user experience.
Global Scalability: With cross-region replication, organizations can distribute workloads across multiple regions to accommodate growing demand and scale resources dynamically. This scalability ensures that applications can handle increased traffic and maintain optimal performance regardless of geographical location.
Cross-region data replication is a fundamental aspect of AWS architecture, providing resilience, scalability, and performance optimization for cloud-based applications and services. By strategically replicating data across multiple regions, organizations can enhance their disaster recovery capabilities, ensure compliance with regulations, and deliver a seamless user experience to a global audience.
Understanding AWS Regions and Availability Zones

Overview of AWS Regions:
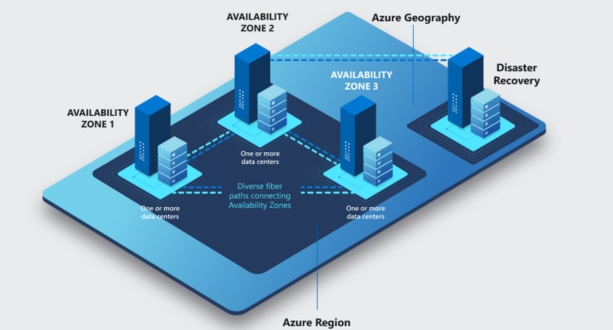
AWS (Amazon Web Services) divides its infrastructure into regions, which are separate geographic areas around the world. Each region is a separate geographic area, and they are designed to be isolated from each other in terms of infrastructure failures. This means that a problem in one region should not affect the operations of another region. AWS currently operates in multiple regions worldwide, including regions such as North America, Europe, Asia Pacific, and others.
Explanation of Availability Zones:
Within each AWS region, there are multiple Availability Zones (AZs). Availability Zones are distinct locations within a region that are engineered to be isolated from failures in other Availability Zones. They are interconnected with low-latency links to provide high-availability and fault tolerance. Each Availability Zone typically consists of one or more data centers, although AWS doesn’t publicly disclose the exact number or location of data centers within each Availability Zone. The goal of having multiple Availability Zones within a region is to provide redundancy and ensure high availability for applications and services deployed on AWS.
Significance in Data Replication:
The presence of multiple Availability Zones within a region is crucial for ensuring data replication and high availability of applications and services. Data replication involves copying data across multiple locations to ensure redundancy and fault tolerance. By deploying resources across multiple Availability Zones within a region, AWS customers can design their applications to replicate data across these zones, thereby ensuring that their applications remain available even in the event of failures in one Availability Zone. This replication can be achieved using various AWS services such as Amazon S3 for object storage, Amazon RDS for databases, and Amazon DynamoDB for NoSQL databases, among others.
AWS Regions represent separate geographic areas, Availability Zones are distinct locations within each region engineered for fault tolerance, and understanding both is essential for designing highly available and fault-tolerant applications on AWS by leveraging data replication across multiple Availability Zones.
AWS Cross-Region Data Replication Overview
Cross-region data replication is a process in which data is duplicated or synchronized across different geographic regions within a cloud computing environment, specifically within Amazon Web Services (AWS) infrastructure. This ensures that data is available and accessible even if one region experiences a failure or outage, thus improving data availability, durability, and disaster recovery capabilities.
What is Cross-Region Data Replication?
Cross-region data replication involves copying data from one AWS region to another, typically using AWS services like Amazon S3 (Simple Storage Service), Amazon RDS (Relational Database Service), Amazon DynamoDB, or third-party tools. This replication can be synchronous or asynchronous, depending on the requirements of the application and the chosen replication strategy. Synchronous replication ensures that data is replicated in real-time, while asynchronous replication may introduce some latency but can be more scalable and cost-effective.
Why Is It Important?
- High Availability: Cross-region data replication enhances data availability by ensuring that copies of data are stored in multiple geographic locations. In case of an outage or failure in one region, applications can seamlessly failover to another region with minimal disruption to operations.
- Disaster Recovery: It provides robust disaster recovery capabilities by enabling businesses to recover data and applications in the event of a catastrophic failure or natural disaster affecting an entire region.
- Compliance and Data Sovereignty: Some regulatory requirements or business policies may necessitate data to be stored in specific geographic regions for compliance or data sovereignty reasons. Cross-region replication allows businesses to comply with these regulations while still leveraging the benefits of cloud computing.
- Reduced Latency: By replicating data closer to end-users or customers in different regions, organizations can reduce latency and improve the overall performance of their applications and services.
Use Cases
- Global Application Deployment: Companies with a global user base can use cross-region data replication to ensure low-latency access to data and applications for users in different geographic regions.
- Multi-Region Disaster Recovery: Businesses can implement cross-region replication as part of their disaster recovery strategy to ensure business continuity in case of regional outages or disasters.
- Compliance and Data Residency: Organizations subject to data residency or compliance regulations can replicate data across regions to meet regulatory requirements while leveraging the scalability and flexibility of the cloud.
- Content Distribution: Content providers can replicate media files, documents, or other digital assets across multiple regions to improve the performance of content delivery to users worldwide.
Cross-region data replication is a critical aspect of cloud infrastructure design for ensuring high availability, disaster recovery, compliance, and improved performance for global applications and services hosted on AWS.
AWS Services for Cross-Region Data Replication
Amazon S3:
Cross-Region Replication (CRR): Amazon S3 offers Cross-Region Replication, which automatically replicates data across different AWS regions. This feature helps in achieving data redundancy, disaster recovery, and low-latency access to data for users located in different geographical regions. With CRR, you can set up rules to replicate objects from a source bucket in one region to a destination bucket in another region. This ensures that your data remains available even in the event of a regional outage.
Bucket Policies and Versioning: Amazon S3 also supports bucket policies and versioning, which are essential for managing data replication and maintaining data integrity across regions. Bucket policies allow you to define access controls and permissions for your S3 buckets, ensuring that data replication processes adhere to security and compliance requirements. Versioning enables you to preserve, retrieve, and restore every version of every object stored in your S3 buckets, providing additional protection against accidental deletion or modification of data during replication.
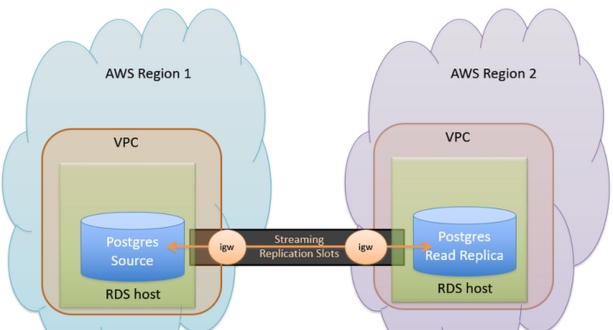
Amazon RDS:
Read Replicas Across Regions: Amazon RDS (Relational Database Service) offers the capability to create read replicas of your database instances across different AWS regions. Read replicas help offload read traffic from the primary database instance, improving read scalability and performance. By deploying read replicas in multiple regions, you can distribute read workload geographically closer to your users, reducing latency and providing a better user experience. Additionally, read replicas can also serve as failover targets in case of primary database failure.
Multi-Region Deployment Options: Amazon RDS supports multi-region deployment options, allowing you to deploy primary database instances and read replicas in different AWS regions for disaster recovery, data locality, and global scalability. You can choose from various replication options, such as synchronous or asynchronous replication, based on your application’s requirements for data consistency and latency. Multi-region deployment enhances fault tolerance and availability by ensuring that your database remains accessible even if an entire AWS region becomes unavailable due to a disaster or outage.
Strategies for Cross-Region Data Replication
Active-Passive Replication:
- Active-passive replication involves maintaining a primary (active) database instance in one region and a secondary (passive) instance in another region.
- In this setup, the primary database handles all read and write operations, while the secondary instance remains passive, typically serving as a backup.
- The secondary instance synchronizes data periodically or in near real-time with the primary instance to ensure data consistency and availability in case of failover.
- Failover occurs when the primary database becomes unavailable due to planned maintenance, network issues, or disasters. During failover, operations switch to the secondary instance to ensure continuous service.
Active-Active Replication:
- Active-active replication involves maintaining multiple synchronized database instances across different regions, all actively serving read and write requests simultaneously.
- This setup aims to distribute the workload evenly across regions, providing low-latency access to users regardless of their geographical location.
- Each database instance in an active-active setup acts both as a primary and secondary instance, capable of handling read and write operations independently.
- Synchronization mechanisms ensure that data updates made in one region are propagated to all other instances in near real-time, maintaining data consistency across the distributed system.
Disaster Recovery Planning:
- Disaster recovery planning involves preparing and implementing strategies to ensure business continuity in the event of a disaster or unexpected outage that affects data centers or infrastructure.
- Cross-region data replication plays a crucial role in disaster recovery by providing redundancy and failover capabilities across geographically dispersed regions.
- Organizations develop comprehensive disaster recovery plans that outline procedures for detecting, responding to, and recovering from disasters, minimizing downtime and data loss.
- These plans often include provisions for data backup, failover mechanisms, network redundancy, and recovery point objectives (RPOs) and recovery time objectives (RTOs) to guide the recovery process.
Data Consistency:
- Data consistency refers to ensuring that all copies of data across distributed systems remain synchronized and up-to-date.
- In cross-region data replication, maintaining data consistency is essential to ensure that users receive accurate and reliable information regardless of their location.
- Various techniques, such as multi-version concurrency control (MVCC), distributed transactions, and conflict resolution mechanisms, are used to manage data consistency in distributed environments.
- Organizations must carefully design their replication strategies and choose appropriate consistency models based on their application requirements, balancing between consistency, availability, and partition tolerance (CAP theorem).
Benefits of Cross-Region Data Replication
High Availability:
Cross-region data replication ensures that even if one region experiences an outage or downtime, the data remains available from other replicated regions.
This redundancy enhances the overall availability of the system, minimizing downtime and ensuring uninterrupted access to data and services for users.
Disaster Recovery:
By replicating data across multiple regions, organizations can create robust disaster recovery mechanisms.
In the event of a catastrophic failure or natural disaster affecting one region, data stored in other regions can be used to quickly restore services and operations, minimizing the impact on business continuity.
Reduced Latency for Global Users:
Placing data closer to end-users across different regions reduces latency, improving the overall user experience.
When users access data from a nearby replicated region, they experience faster response times and lower network latency compared to accessing data from a distant region.
Compliance and Data Residency:
Some regulations and compliance requirements mandate that data must be stored within specific geographical regions or jurisdictions.
Cross-region data replication allows organizations to comply with these requirements by storing data in multiple regions while ensuring it remains within the necessary boundaries.
This ensures data residency compliance and reduces the risk of non-compliance penalties.
Best Practices for Implementing Cross-Region Data Replication
Proper Region Selection:
Selecting the right regions for data replication is crucial for ensuring optimal performance, compliance, and disaster recovery preparedness. Consider factors such as proximity to users, regulatory requirements, latency, and data sovereignty laws. Evaluate the availability of data centers in different regions and choose those that offer the best balance of performance and compliance for your specific use case.
Security Considerations:
Security should be a top priority when implementing cross-region data replication. Ensure that data is encrypted both in transit and at rest to protect it from unauthorized access or interception. Implement strong access controls, authentication mechanisms, and authorization policies to restrict access to replicated data. Regularly audit and monitor access logs for any suspicious activities. Additionally, consider implementing techniques such as tokenization or anonymization to further protect sensitive data.
Monitoring and Alerts:
Establish comprehensive monitoring and alerting mechanisms to continuously monitor the health and performance of cross-region data replication. Set up monitoring for key metrics such as replication lag, throughput, latency, and error rates. Utilize monitoring tools and services to track the replication status in real-time and set up alerts to notify administrators of any anomalies or failures. Proactive monitoring helps identify issues early and enables prompt resolution to prevent data loss or downtime.
Testing and Validation:
Regularly test and validate the cross-region data replication process to ensure its reliability, consistency, and integrity. Develop robust testing procedures and scenarios to simulate various failure scenarios such as network outages, region failures, or data corruption incidents. Verify that replicated data matches the source data accurately and conduct performance testing to assess the replication speed and efficiency. Document testing results and use them to refine replication processes and address any identified issues or gaps.
Challenges and Considerations
Cost Management:
Cost management involves effectively controlling and optimizing the expenses associated with various aspects of a project or operation. In the context of whatever you’re referring to, whether it’s a business operation, a technological implementation, or something else, cost management is crucial for ensuring financial sustainability and maximizing profitability.
This involves budgeting, tracking expenses, identifying cost-saving opportunities, and making informed decisions regarding resource allocation. Factors such as infrastructure costs, software licensing fees, personnel expenses, and ongoing maintenance costs all contribute to the overall cost structure. Implementing cost-effective solutions, negotiating favorable contracts with vendors, and regularly reviewing expenses are some strategies for effective cost management.
Data Transfer Costs:
Data transfer costs refer to the charges associated with moving data between different locations or systems, particularly in the context of cloud computing, networking, or data storage services. These costs can vary depending on factors such as the volume of data transferred, the distance it needs to travel, and the service provider’s pricing model. Organizations must carefully monitor and manage data transfer costs to prevent unexpected expenses from exceeding budgetary constraints.
Strategies for controlling data transfer costs may include optimizing data compression techniques, utilizing caching mechanisms to reduce redundant transfers, strategically selecting data storage locations based on proximity to users or other systems, and leveraging content delivery networks (CDNs) to minimize latency and bandwidth usage.
Network Latency:
Network latency refers to the delay or lag that occurs when data packets are transmitted between devices over a network. It is influenced by various factors such as the distance between the communicating devices, the quality of network infrastructure, congestion levels, and the processing time required by intermediate network devices. High network latency can degrade the performance of applications and services, leading to sluggish response times, poor user experience, and decreased productivity.
Mitigating network latency requires implementing efficient networking protocols, optimizing network configurations, utilizing caching mechanisms to reduce round-trip times, and strategically deploying content delivery networks (CDNs) to minimize the distance data travels. Additionally, technologies such as edge computing can help reduce latency by processing data closer to the point of origin or consumption.
Regulatory Compliance:
Regulatory compliance refers to the adherence to laws, regulations, and industry standards that govern specific activities or industries. In the context of data management, regulatory compliance is particularly important due to the sensitivity and privacy implications of handling personal or confidential information. Organizations must ensure that their data management practices align with relevant regulations such as the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), or the Payment Card Industry Data Security Standard (PCI DSS), among others.
This may involve implementing robust security measures to protect data from unauthorized access or breaches, establishing data governance frameworks to ensure transparency and accountability, and conducting regular audits or assessments to validate compliance. Non-compliance can result in severe penalties, legal consequences, reputational damage, and loss of customer trust. Therefore, organizations must prioritize regulatory compliance as an integral aspect of their data management strategy.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}