Introduction to Serverless Architecture

Serverless architecture is a computing model where the cloud provider dynamically manages the allocation and provisioning of servers.
Definition of Serverless Architecture:
Serverless architecture, sometimes referred to as Function as a Service (FaaS), is a cloud computing model where cloud providers manage the infrastructure needed to run code, allowing developers to focus on writing application logic. In serverless architecture, applications are broken down into smaller functions that are deployed and executed individually in response to specific events or triggers.
Evolution from Monolithic to Microservices:
Monolithic architecture involves building applications as a single, indivisible unit, where all the components are tightly integrated. This can lead to challenges in scalability, maintainability, and deployment. Microservices architecture, on the other hand, decomposes applications into smaller, loosely coupled services that can be developed, deployed, and scaled independently. Serverless architecture takes this a step further by abstracting away the infrastructure entirely, allowing developers to focus on building individual functions that can be easily integrated into a larger application.
Benefits of Serverless Microservices on AWS:

- Scalability: AWS automatically scales resources up or down based on demand, so you don’t need to worry about provisioning or managing servers.
- Cost-Effectiveness: With serverless architecture, you only pay for the compute resources used by your functions, which can result in cost savings compared to traditional hosting models.
- High Availability: AWS handles replication and distribution of functions across multiple availability zones, ensuring high availability and fault tolerance.
- Faster Time to Market: Serverless architecture allows developers to focus on writing code rather than managing infrastructure, which can accelerate development cycles and time to market.
- Increased Flexibility: Serverless architecture makes it easy to integrate with other AWS services and third-party APIs, enabling developers to build complex, event-driven applications with ease.
Understanding AWS Serverless Components
AWS Lambda:

AWS Lambda is a compute service that allows you to run code without provisioning or managing servers. It follows the Function as a Service (FaaS) model.
You can upload your code (written in supported languages like Node.js, Python, Java, etc.) and Lambda takes care of scaling and managing the underlying infrastructure needed to run your code in response to incoming requests or events.
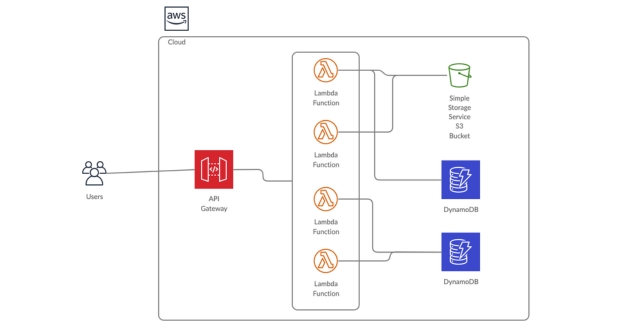
Lambda functions can be triggered by various AWS services, such as API Gateway, S3, DynamoDB, or by custom events.
Amazon API Gateway:
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale.
It allows you to create RESTful APIs or WebSocket APIs to communicate with AWS Lambda functions, other AWS services, or external HTTP endpoints.
API Gateway supports various features like authentication and authorization, request and response transformations, rate limiting, and caching.
AWS DynamoDB:
AWS DynamoDB is a fully managed NoSQL database service provided by AWS.
It offers low-latency, scalable performance with seamless scalability and high availability.
DynamoDB supports key-value and document data models and provides features like single-digit millisecond response times, automatic scaling, and built-in security.
AWS Step Functions:
AWS Step Functions is a serverless orchestration service that allows you to coordinate and sequence AWS Lambda functions and other AWS services into workflows.
It helps you build complex workflows by defining a series of steps, handling errors, and retrying failed steps automatically.
Step Functions provide a visual workflow editor and support for state machines, making it easier to visualize and manage your application’s workflows.
AWS EventBridge:
AWS EventBridge is a serverless event bus service that makes it easy to connect different applications using events.
It decouples event producers from event consumers, allowing you to build event-driven architectures that are more scalable and resilient.
EventBridge supports event routing, transformation, and filtering, and it integrates with various AWS services and SaaS applications.
Designing Serverless Microservices on AWS
Principles of designing serverless microservices:
- Statelessness: Each microservice should be stateless, meaning it doesn’t maintain any session data. This allows for easy scaling and fault tolerance.
- Event-driven architecture: Serverless microservices typically operate in response to events triggered by various sources such as HTTP requests, database changes, or messages from event buses like Amazon SNS or Amazon SQS.
- Loose coupling: Microservices should be designed with loose coupling to allow for independent development, deployment, and scaling. They should communicate through well-defined APIs or events.
- Function-as-a-Service (FaaS): Utilize AWS Lambda or similar services to deploy microservices without managing servers, allowing for rapid development and deployment.
Decoupling services for scalability and resilience:
- Break down the application into smaller, independent services that can be scaled independently. Each service should have a specific responsibility or function.
- Utilize event-driven architecture to decouple services. This allows for asynchronous communication and helps prevent cascading failures.
- Implement retries and exponential backoff mechanisms to handle failures gracefully and ensure resilience.
Design patterns for serverless microservices:
- API Gateway with Lambda integration: Use Amazon API Gateway to expose RESTful APIs and integrate with AWS Lambda functions for handling requests.
- Event sourcing: Store all changes to application state as a sequence of events. This pattern enables scalability, auditability, and replayability of events.
- Saga pattern: Implement long-running, distributed transactions using a series of compensating actions. This helps maintain consistency across multiple services.
Best practices for deployment and monitoring:
- Continuous Deployment (CD): Automate the deployment process using tools like AWS CodePipeline and AWS CodeDeploy to ensure fast and reliable releases.
- Infrastructure as Code (IaC): Define and provision AWS resources using Infrastructure as Code tools like AWS CloudFormation or AWS CDK to manage infrastructure changes consistently.
- Logging and Monitoring: Use AWS CloudWatch for monitoring Lambda functions, API Gateway, and other AWS services. Implement centralized logging with services like AWS CloudTrail and AWS X-Ray for distributed tracing.
- Security: Follow AWS best practices for securing serverless applications, including implementing least privilege access, encrypting data in transit and at rest, and regularly auditing permissions.
Building and Deploying Serverless Microservices
Development environment setup on AWS:
Developers start by setting up their development environment on AWS. This typically involves creating an AWS account, configuring access credentials, and setting up tools such as AWS CLI (Command Line Interface) or SDKs (Software Development Kits) for their preferred programming language.
Writing Lambda functions in supported languages:
AWS Lambda is a serverless compute service that allows developers to run code without provisioning or managing servers. Developers write the business logic of their microservices as Lambda functions. Lambda supports multiple programming languages such as Python, Node.js, Java, Go, and .NET, allowing developers to choose the language they are most comfortable with.
Configuring API Gateway endpoints:
AWS API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. Developers configure API Gateway endpoints to expose their Lambda functions as HTTP endpoints. They define the HTTP methods (GET, POST, PUT, DELETE, etc.), request/response mappings, authentication, authorization, and other settings using API Gateway’s intuitive interface or through infrastructure-as-code tools like AWS CloudFormation or AWS CDK (Cloud Development Kit).
Defining data models and interactions with DynamoDB:
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and predictable performance with seamless scalability. Developers define the data models for their microservices and design the interactions with DynamoDB to store and retrieve data. They use DynamoDB’s features such as tables, items, attributes, primary keys, secondary indexes, and query capabilities to efficiently manage and query data.
Orchestrating workflows with Step Functions:
AWS Step Functions is a serverless orchestration service that allows developers to coordinate multiple AWS services into serverless workflows. Developers use Step Functions to define the flow of activities in their microservices, including conditional logic, error handling, retries, and parallel execution. They can model complex business processes as state machines using Step Functions’ visual designer or JSON-based state machine language.
Scaling and Performance Optimization
Autoscaling Lambda Functions:
- Lambda functions are the building blocks of serverless applications, handling discrete tasks or microservices.
- Autoscaling Lambda functions involve dynamically adjusting the number of concurrent executions based on demand. When traffic increases, Lambda automatically provisions more resources to handle the load.
- This ensures that the application can handle spikes in traffic without manual intervention, providing seamless scalability.
- Key factors to consider include setting appropriate concurrency limits, monitoring invocation rates, and optimizing function duration to minimize costs.
DynamoDB Capacity Management:
- DynamoDB is a fully managed NoSQL database service provided by AWS, commonly used in serverless architectures due to its scalability and performance.
- Capacity management involves configuring read and write capacity units (RCUs and WCUs) to match the workload requirements.
- Utilize DynamoDB auto-scaling to automatically adjust throughput capacity based on usage patterns, ensuring consistent performance without over-provisioning or under-provisioning.
- Implement best practices for partition key selection, data modeling, and indexing to optimize query performance and minimize costs.
Optimizing API Gateway Performance:
- API Gateway acts as a front door for serverless applications, allowing clients to securely access backend services via RESTful APIs or WebSocket connections.
- Performance optimization involves reducing latency, increasing throughput, and improving scalability.
- Techniques include caching responses at API Gateway to reduce backend load and latency for frequently accessed resources.
- Use efficient integration types (e.g., Lambda proxy integration, HTTP integration) and optimize endpoint configurations (e.g., caching settings, throttling limits) based on traffic patterns and application requirements.
Caching Strategies for Serverless Microservices:
- Caching is essential for improving the performance and reducing the cost of serverless microservices by reducing the need to retrieve data from backend services repeatedly.
- Implement caching mechanisms at various layers of the application stack, including API Gateway, Lambda functions, and DynamoDB.
- Consider using managed caching services like Amazon ElastiCache or Amazon CloudFront for content caching to serve static assets or dynamic content with low latency.
- Leverage in-memory caching within Lambda functions using libraries like Redis or Memcached for storing frequently accessed data or expensive computation results.
Security and Compliance Considerations
Authentication and Authorization in Serverless Architecture:
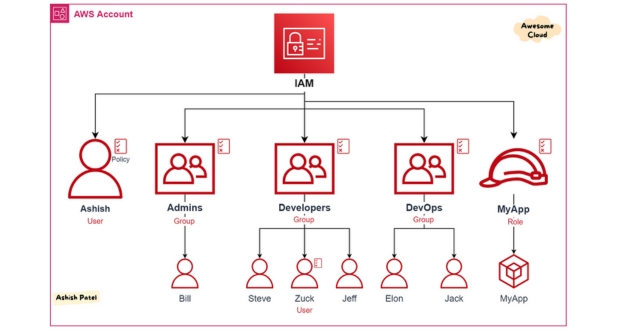
- Authentication: Ensuring that only authorized users or systems can access your serverless functions is crucial. This often involves using authentication protocols like OAuth, OpenID Connect, or API keys. Multi-factor authentication (MFA) can add an extra layer of security.
- Authorization: Once authenticated, users or systems must have appropriate permissions to access different parts of the serverless architecture. This is typically managed through access control mechanisms such as IAM (Identity and Access Management) policies in cloud providers like AWS, Azure, or Google Cloud Platform.
Securing Data at Rest and in Transit:
- Data at Rest: Serverless applications often rely on databases, storage services, or file systems to persist data. Encrypting this data at rest using techniques like AES encryption or managed encryption services provided by cloud providers ensures that even if unauthorized access occurs, the data remains secure.
- Data in Transit: When data is transmitted between components within the serverless architecture or between the client and serverless functions, it’s essential to use secure communication protocols such as HTTPS/TLS. Transport layer security ensures that data remains confidential and integral during transit.
Compliance with Industry Regulations:
- Depending on the industry in which your serverless application operates, there may be specific regulations and compliance standards that you must adhere to. For instance, in healthcare, there’s HIPAA (Health Insurance Portability and Accountability Act), in finance, there’s PCI DSS (Payment Card Industry Data Security Standard), and in Europe, there’s GDPR (General Data Protection Regulation).
- Compliance with these regulations involves implementing specific security measures, data handling practices, and audit capabilities within your serverless architecture. For example, ensuring that personally identifiable information (PII) is handled securely, maintaining audit logs of data access and modifications, and regularly assessing and updating security controls to meet evolving compliance requirements.
Cost Optimization Strategies
Understanding AWS Lambda pricing model:
- AWS Lambda pricing is based on the number of requests and the compute time consumed to execute your functions. It’s crucial to understand how this pricing model works to effectively estimate costs.
- AWS charges for the number of requests your functions receive, measured in millions of requests per month. Additionally, AWS measures the compute time in increments of 100 milliseconds, rounding up to the nearest increment for each execution.
- By understanding these pricing components, you can optimize your functions to minimize unnecessary requests and reduce compute time, thus lowering costs.
Optimizing resource allocation for cost efficiency:
- Properly sizing the allocated resources for your Lambda functions is key to cost optimization. Over-provisioning can lead to unnecessary expenses, while under-provisioning might impact performance.
- You can optimize resource allocation by adjusting the memory allocated to your functions. Lambda charges are based on the amount of memory allocated to a function, with corresponding CPU and other resources. Optimizing memory allocation can directly impact cost efficiency.
- Additionally, optimizing the execution time of your functions by improving code efficiency and minimizing dependencies can help reduce costs.
Analyzing cost using AWS Cost Explorer and Billing Dashboard:
- AWS provides tools like Cost Explorer and the Billing Dashboard to help users analyze and manage their cloud costs effectively.
- Cost Explorer allows you to visualize and analyze your AWS spending patterns over time. You can segment costs by service, instance type, region, and more, enabling you to identify areas for optimization.
- The Billing Dashboard provides a summary of your current AWS charges, including detailed billing reports that can be used for cost allocation and analysis.
- By regularly monitoring your AWS costs using these tools, you can identify cost trends, set budgets, and implement cost-saving measures proactively.
Monitoring and Logging
AWS CloudWatch for Monitoring Serverless Applications:
- AWS CloudWatch is a monitoring and observability service provided by Amazon Web Services.
- For serverless applications, CloudWatch provides insights into various metrics such as Lambda function invocations, error rates, execution duration, and resource utilization.
- It allows you to set up dashboards to visualize these metrics, enabling you to monitor the health and performance of your serverless architecture.
- CloudWatch Logs can capture logs generated by Lambda functions and other AWS services, providing valuable information for troubleshooting and performance analysis.
Setting Up Alarms and Notifications:
- In CloudWatch, you can set up alarms based on predefined thresholds for metrics such as error rates or execution duration.
- When these thresholds are breached, CloudWatch triggers alarms, allowing you to take proactive actions.
- Notifications can be configured to alert designated stakeholders via email, SMS, or other means, ensuring that the appropriate personnel are informed of any issues promptly.
Logging Best Practices for Troubleshooting:
- Effective logging is crucial for troubleshooting serverless applications.
- It’s recommended to include relevant information in logs such as timestamps, request IDs, and any contextual data that can help in diagnosing issues.
- Structured logging formats can make log data more parseable and easier to analyze.
- Leveraging CloudWatch Logs Insights, you can query and analyze log data efficiently, enabling quick identification of issues and root causes.
- Implementing centralized logging solutions like AWS CloudWatch Logs or integrating with third-party logging services can streamline log management and analysis across multiple services and environments.
Challenges and Limitations
Vendor Lock-in and Interoperability Concerns:
- Vendor Lock-in: Many cloud service providers offer proprietary tools and services that can tie a business to a specific vendor. This can lead to dependency issues, making it difficult to switch providers or integrate with other platforms.
- Interoperability: Different cloud platforms may use different technologies, APIs, or standards, leading to interoperability challenges when trying to integrate services or migrate applications across multiple clouds. This can hinder flexibility and increase complexity for businesses operating in a multi-cloud environment.
Performance Bottlenecks and Cold Starts:
- Performance Bottlenecks: Cloud applications may experience performance issues due to factors such as network latency, resource contention, or limitations in the cloud provider’s infrastructure. Identifying and mitigating these bottlenecks can be challenging and may require optimization of code, architecture, or resource allocation.
- Cold Starts: In serverless computing environments, there can be delays in the execution of functions due to the initialization of resources, known as “cold starts.” These delays can impact application responsiveness and user experience, especially in scenarios where rapid scaling or sporadic usage patterns are involved.
Debugging and Troubleshooting Challenges:
- Distributed Nature: Cloud applications often comprise distributed systems with multiple components and services. Debugging and troubleshooting issues in such environments can be complex, as problems may arise from interactions between different components or services.
- Limited Visibility: Cloud providers may offer limited visibility into the underlying infrastructure or runtime environment, making it challenging to diagnose issues effectively. This lack of visibility can hinder root cause analysis and prolong resolution times.
- Tooling and Monitoring: Effective debugging and troubleshooting require robust tooling and monitoring capabilities. However, integrating and managing these tools across diverse cloud environments can be challenging, leading to gaps in monitoring coverage or inconsistent diagnostic workflows.
Addressing these challenges often requires a combination of technical expertise, architectural best practices, and careful consideration of factors such as vendor lock-in, performance optimization, and debugging strategies. Organizations adopting cloud technologies must proactively assess and mitigate these challenges to ensure the reliability, scalability, and efficiency of their cloud-based applications.
Conclusion
In conclusion, AWS Serverless Microservices offer significant advantages in terms of scalability, cost savings, agility, and simplified operations. However, it’s essential to carefully consider the challenges and considerations associated with adopting this architecture and implement best practices to mitigate risks effectively. Overall, AWS Serverless provides a powerful platform for building and deploying modern, scalable, and resilient applications.
Benefits include reduced operational overhead, cost savings, scalability, increased developer productivity, and the ability to focus on business logic rather than infrastructure management.
Commonly used AWS services include AWS Lambda for compute, Amazon API Gateway for API management, Amazon DynamoDB for NoSQL database, Amazon S3 for object storage, and AWS Step Functions for orchestrating serverless workflows.
AWS Lambda allows you to run code without provisioning or managing servers. Each Lambda function is triggered by specific events and scales automatically in response to incoming requests.
Amazon API Gateway acts as a front door for serverless applications, allowing you to create, publish, maintain, monitor, and secure APIs at scale. It integrates seamlessly with AWS Lambda to expose Lambda functions as HTTP endpoints.
AWS DynamoDB is a fully managed NoSQL database service that provides single-digit millisecond latency at any scale. It’s commonly used in serverless architectures for storing application data due to its seamless integration, scalability, and performance.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}