Introduction to AWS Aurora
AWS Aurora is a relational database service provided by Amazon Web Services (AWS) that is designed to offer high performance, scalability, and reliability while being compatible with MySQL and PostgreSQL. It aims to address the limitations and challenges of traditional databases by leveraging cloud infrastructure and innovative architecture.
Overview of AWS Aurora
AWS Aurora is a fully managed database service that combines the performance and availability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. It is built for the cloud, offering features such as automatic scaling, fault tolerance, and data replication across multiple availability zones.
One of the key differences between AWS Aurora and traditional databases is its underlying architecture. Aurora uses a distributed, shared-storage model that separates compute and storage layers. This architecture allows it to scale out horizontally by adding more storage or compute nodes, which helps improve performance and availability without downtime.
Furthermore, AWS Aurora implements a unique storage system that is purpose-built for cloud environments. It uses a quorum-based replication mechanism to replicate data across multiple storage nodes, ensuring high availability and durability. Additionally, it provides instant crash recovery and continuous backups to protect against data loss.
Key features and benefits

- High performance: AWS Aurora is optimized for performance, delivering up to five times the throughput of standard MySQL databases and three times the throughput of standard PostgreSQL databases. It achieves this by using a distributed, SSD-backed storage system and a multi-threaded, parallel query execution engine.
- Scalability: Aurora allows you to easily scale your database instance up or down based on your application’s needs. You can increase storage capacity or add read replicas to handle growing workloads without downtime or performance degradation.
- High availability: With built-in replication and automated failover, AWS Aurora provides high availability and data durability. It automatically replicates data across multiple availability zones and continuously monitors the health of your database instances to quickly detect and recover from failures.
- Compatibility: AWS Aurora is compatible with MySQL and PostgreSQL, allowing you to seamlessly migrate your existing databases to the Aurora platform without making any changes to your applications. It supports popular database engines, SQL syntax, and client libraries, making it easy to get started.
- Cost-effectiveness: Despite its advanced features, AWS Aurora is cost-effective compared to traditional databases. It offers pay-as-you-go pricing with no upfront costs or long-term commitments, allowing you to only pay for the resources you use.
AWS Aurora is a powerful and versatile database service that offers high performance, scalability, and availability for modern cloud applications. Its innovative architecture and advanced features make it a popular choice for organizations looking to leverage the benefits of the cloud for their relational databases.
Understanding Database Management on AWS Aurora
Setting up AWS Aurora: Steps involved and considerations:
- Choosing the Right Configuration: AWS Aurora offers different configurations depending on your workload requirements. You’ll need to consider factors like storage type (SSD or HDD), instance size, and replication options (single-master, multi-master).
- Launching Aurora Cluster: You can set up Aurora through the AWS Management Console, AWS CLI, or AWS CloudFormation templates. During setup, you’ll specify details such as the cluster identifier, instance type, security group, and VPC.
- Security Considerations: Ensure proper security measures are in place, such as configuring VPC security groups, IAM roles, encryption at rest and in transit, and enforcing least privilege access controls.
- Monitoring and Alerting: Configure CloudWatch metrics and set up alarms to monitor the health and performance of your Aurora clusters. Consider using AWS Trusted Advisor to receive recommendations for optimizing your Aurora setup.
Data modeling and schema design:
- Normalization: Design your database schema to adhere to normalization principles to minimize redundancy and improve data integrity.
- Denormalization: Depending on your query patterns and performance requirements, selectively denormalize certain tables to optimize read performance.
- Partitioning: Utilize Aurora’s partitioning features to distribute data across multiple underlying storage nodes, improving scalability and performance.
- Indexing: Design appropriate indexes to support your query patterns efficiently. Aurora supports traditional B-tree indexes as well as advanced indexing techniques like Bitmap Indexes and Partial Indexes.
Query optimization techniques specific to Aurora:
Use Analyze Command: Utilize the ANALYZE command to gather statistics on tables and indexes, which helps the query planner make better decisions.
- Query Caching: Aurora features a query cache that can improve the performance of frequently executed queries by caching their results.
- Materialized Views: Implement materialized views to precompute and store the results of expensive queries, reducing query execution time for subsequent requests.
- Parallel Query Processing: Aurora supports parallel query execution, allowing certain queries to be split into smaller tasks and processed concurrently for faster results.
- Query Profiling: Use tools like Amazon RDS Performance Insights or native database profiling tools to identify slow-performing queries and optimize them accordingly.
- Query Rewrite: Rewrite complex queries to more efficient forms, utilizing features like window functions, common table expressions (CTEs), and subqueries judiciously.
Performance Optimization Techniques
Utilizing read replicas for scaling read operations:
Read replicas are essentially copies of your primary database that are synchronized asynchronously. By directing read operations to these replicas instead of the primary database, you can distribute the read workload across multiple instances, thus improving read performance and scalability. This technique is particularly useful in scenarios where the application experiences a high volume of read requests compared to writes. However, it’s important to ensure that data consistency requirements are met, as read replicas might not always have the most up-to-date data.
Indexing strategies for improved query performance:
Indexes are data structures that enhance the speed of data retrieval operations by allowing the database engine to quickly locate specific rows based on the values of certain columns. Choosing the right columns to index and optimizing index design can significantly improve query performance. However, excessive indexing can lead to overhead during write operations, so it’s essential to strike a balance between query performance and the impact on write operations.
Leveraging caching mechanisms:
Caching involves storing frequently accessed data in memory or in a fast-access storage layer, such as Redis or Memcached, to reduce the need to retrieve the same data repeatedly from the database. This can greatly reduce latency and improve overall system performance. Caching can be implemented at various levels, including application-level caching, database query caching, and object-level caching. However, it’s important to carefully manage cache invalidation to ensure that cached data remains consistent with the underlying data source.
Fine-tuning parameters for optimal performance:
Many databases and applications offer a wide range of configuration parameters that can be adjusted to optimize performance based on specific workload characteristics and hardware resources. These parameters may include settings related to memory allocation, disk I/O, query optimization, connection pooling, and concurrency control. Fine-tuning these parameters requires careful monitoring and experimentation to identify the optimal configuration for your particular use case. Additionally, it’s important to periodically review and adjust these parameters as workload patterns change over time.
Data Security and Compliance Measures
Encryption options for data at rest and in transit:
- Data at rest: This refers to data that is stored in a database, file system, or any other storage medium. Encryption at rest involves encoding data so that it remains unreadable unless decrypted with the appropriate key. This ensures that even if unauthorized individuals gain access to the storage medium, they cannot make sense of the data without the encryption key.
- Data in transit: This refers to data being transmitted between two points, such as over a network or the internet. Encryption in transit involves encrypting the data as it travels from one location to another, preventing unauthorized interception and access. Common protocols for encrypting data in transit include SSL/TLS for web traffic and VPNs for secure network communication.
Identity and access management controls:
- This involves implementing measures to control who can access data and resources within a system or organization. This typically includes user authentication (verifying the identity of users), authorization (determining what actions users are allowed to perform), and auditing (monitoring and recording user activities). Identity and access management (IAM) controls help ensure that only authorized individuals can access sensitive data, reducing the risk of data breaches and unauthorized access.
Compliance certifications and adhering to industry standards:
- Many industries and jurisdictions have specific regulations and standards governing the handling of sensitive data. Compliance certifications demonstrate that an organization meets the requirements outlined in these regulations and standards. Examples include GDPR (General Data Protection Regulation) in the European Union, HIPAA (Health Insurance Portability and Accountability Act) in the United States, and PCI DSS (Payment Card Industry Data Security Standard) for organizations handling credit card information. Adhering to these standards helps ensure that data security and privacy requirements are met, reducing the risk of legal consequences and reputational damage.
Data backup and recovery mechanisms:

Data backup involves creating copies of data to protect against data loss due to accidental deletion, hardware failures, or other disasters. Backup mechanisms ensure that even if primary data is compromised, damaged, or lost, it can be restored from backup copies. Recovery mechanisms involve processes and procedures for restoring data from backups in the event of a data loss incident. This includes defining backup schedules, testing backup systems regularly, and establishing procedures for data restoration. Effective backup and recovery mechanisms are essential for ensuring data availability and continuity of operations in the face of data loss incidents.
Scalability Strategies
Horizontal and Vertical Scaling Options:
Horizontal Scaling: Also known as scaling out, involves adding more machines or nodes to your database system. With horizontal scaling, you distribute the load across multiple machines, which can help improve performance and handle larger workloads. In the context of Aurora, this means adding more Aurora database instances to your cluster.
Vertical Scaling: Also known as scaling up, involves increasing the resources (such as CPU, RAM, or storage) of individual machines in the database system. In the context of Aurora, this could mean upgrading the instance class or storage capacity of your Aurora instances.
Automatic Scaling Features of Aurora:
Amazon Aurora is a fully managed relational database service offered by AWS. It provides automatic scaling capabilities, where it can automatically adjust compute and storage resources based on the workload demands. This ensures optimal performance without the need for manual intervention.
Multi-Master and Global Databases for Distributed Deployments:
Multi-master replication allows multiple database nodes to accept write operations, providing high availability and scalability by distributing write operations across multiple nodes. With Aurora, you can set up multi-master clusters to handle write traffic efficiently.
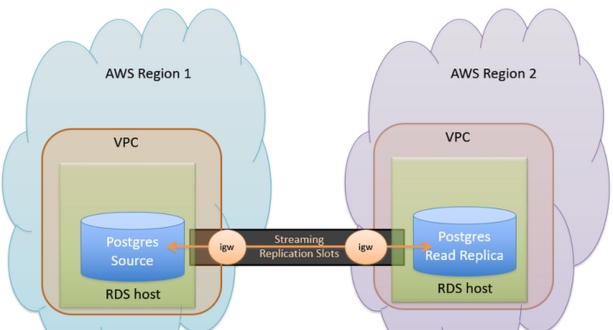
Global databases in Aurora enable you to replicate your data across multiple AWS regions, allowing you to serve read traffic from local replicas in different geographic locations. This enhances performance and provides disaster recovery capabilities.
Utilizing Aurora Serverless for Auto-Scaling:
Aurora Serverless is a configuration option for Amazon Aurora that automatically adjusts database capacity based on the workload. It allows you to run your Aurora database without managing instances, which means it automatically scales up or down based on demand. This is particularly useful for unpredictable workloads or applications with varying usage patterns.
Monitoring and Maintenance Practices
Monitoring Performance Metrics using CloudWatch: CloudWatch is a monitoring service provided by Amazon Web Services (AWS) that allows you to collect and track metrics, monitor log files, set alarms, and automatically react to changes in your AWS resources. When it comes to monitoring performance metrics, CloudWatch provides insights into various aspects of your AWS infrastructure, including CPU utilization, disk I/O, network traffic, and more. By regularly monitoring these metrics, you can gain visibility into the health and performance of your systems and applications.
Setting up Alarms and Notifications: In conjunction with monitoring metrics, it’s crucial to set up alarms and notifications in CloudWatch to proactively respond to any anomalies or issues. Alarms can be configured based on specific thresholds or conditions, such as CPU utilization exceeding a certain percentage or the number of error responses from an application reaching a certain threshold. When an alarm is triggered, CloudWatch can send notifications via various channels like email, SMS, or even trigger automated actions using AWS Lambda functions.
Database Maintenance Tasks like Patching and Upgrades: Database maintenance tasks are essential to ensure the reliability, security, and performance of your databases. This includes activities such as applying patches and updates to the database software, upgrading to newer versions to access new features and performance enhancements, and performing routine maintenance tasks like optimizing indexes and vacuuming tables to reclaim storage space. Automating these tasks where possible can help streamline maintenance efforts and minimize downtime.
Proactive Monitoring for Identifying and Addressing Issues: Proactive monitoring involves continuously monitoring systems and applications to identify potential issues or bottlenecks before they escalate into major problems. This can include analyzing trends over time, setting up predictive analytics models to forecast future performance, and implementing automated remediation actions to resolve common issues without manual intervention. By being proactive, organizations can minimize downtime, optimize resource utilization, and improve overall system reliability.
Monitoring and maintenance practices like those mentioned are essential components of managing a reliable and efficient cloud infrastructure. By leveraging tools like CloudWatch and implementing proactive monitoring strategies, organizations can detect and address issues in a timely manner, optimize resource utilization, and ensure the ongoing health and performance of their systems and applications.
Cost Optimization Strategies
Understanding Aurora Pricing Models:
Aurora offers different pricing models based on usage metrics such as database instance size, storage capacity, and data transfer. Understanding these pricing models helps in making informed decisions about resource allocation and usage.
Aurora pricing typically involves charges for database instance hours, storage capacity used, I/O operations, backup storage, and data transfer. Different pricing tiers exist for different instance sizes and storage capacities.
By comprehensively understanding these pricing models, businesses can optimize their resource usage to minimize costs.
Right-sizing Database Instances:
Right-sizing involves selecting the appropriate instance type and size based on the workload requirements of the application.
Over-provisioning leads to unnecessary expenses, while under-provisioning can result in performance issues. By accurately assessing the workload demands, businesses can choose the most cost-effective instance type and size for their Aurora databases.
Regularly monitoring resource utilization and performance metrics can help identify opportunities for rightsizing database instances.
Utilizing Reserved Instances for Cost Savings:
AWS offers Reserved Instances (RIs), which allow businesses to reserve database instances for a specified duration (e.g., one or three years) in exchange for a discounted hourly rate compared to On-Demand Instances.
By committing to a certain usage volume, businesses can achieve significant cost savings with RIs compared to paying for instances on-demand.
Analyzing historical usage patterns and workload requirements can help determine the appropriate type and quantity of RIs to purchase for Aurora databases.
Implementing Cost Allocation Tags for Resource Tracking:
Cost allocation tags are metadata labels assigned to AWS resources, including Aurora database instances and storage volumes.
Tags enable businesses to categorize and track resource usage and costs based on custom attributes such as department, project, environment (e.g., production, development), or team.
By implementing consistent tagging practices, businesses can gain insights into cost drivers, allocate expenses accurately, and identify areas for cost optimization.
AWS provides tools such as AWS Cost Explorer and AWS Cost and Usage Report to analyze cost allocation data and optimize spending.
Best Practices for Disaster Recovery
Implementing multi-region replication for disaster recovery:
Multi-region replication involves replicating your data and resources across different geographic regions. This ensures that if one region experiences a disaster, such as a natural calamity or a service outage, your data and applications remain available and accessible from another region. By spreading your resources across multiple regions, you reduce the risk of a single point of failure.
This practice often involves leveraging cloud services provided by major cloud providers like Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP), which offer tools and services for easily replicating data across regions.
Automated backups and snapshots:
Regular backups are essential for disaster recovery. Automated backup solutions help ensure that critical data and system configurations are consistently backed up without manual intervention. These backups should be stored securely and ideally in multiple locations to mitigate the risk of data loss.
Snapshots are point-in-time copies of your data or system state. They provide a quick and efficient way to capture the current state of your resources, allowing for fast recovery in case of failures.
Disaster recovery drills and testing:
Regular drills and testing of your disaster recovery plan are crucial to ensure its effectiveness. These drills simulate various disaster scenarios and assess how well your systems, processes, and personnel respond to them.
Through testing, you can identify weaknesses or gaps in your disaster recovery plan and make necessary adjustments to improve resilience and reduce recovery time objectives (RTO) and recovery point objectives (RPO).
Failover and high availability configurations:
Failover refers to the automatic switching of operations to a redundant or standby system in the event of a primary system failure. Implementing failover mechanisms ensures continuous availability of services even when components or entire systems fail.
High availability configurations involve designing systems and architectures in a way that minimizes downtime and ensures uninterrupted service delivery. This often includes redundancy at various levels, load balancing, and active-active or active-passive configurations.
Conclusion
In conclusion, effective management of the AWS Aurora database entails a comprehensive understanding of its architecture, coupled with adherence to best practices across various aspects including performance optimization, cost management, high availability, and security. By implementing strategies such as schema design optimization, query performance tuning, and utilization of AWS services for automation and integration, organizations can harness the full potential of Aurora while ensuring scalability, reliability, and cost-efficiency.
Aurora is built for the cloud, offering features such as automatic scaling, high availability, and fault tolerance. It is designed to handle demanding workloads and offers performance improvements over traditional relational databases.
Some benefits include higher performance, automatic scaling, built-in high availability with replication across multiple availability zones, and lower costs compared to traditional database solutions.
AWS Aurora pricing is based on factors such as instance size, storage, and data transfer. Users pay for the resources they consume on an hourly basis, with options for on-demand or reserved instances.
Aurora replicates data across multiple availability zones within a single AWS region. It uses a quorum-based storage system to ensure that data is durable and available even in the event of hardware failures.
Yes, AWS provides tools and documentation to help users migrate their databases to Aurora from other database engines such as MySQL or PostgreSQL.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}