Introduction of AWS Data Lake Solutions
Definition and Concept of Data Lakes:
- Data lakes are a centralized repository that allows organizations to store all their structured and unstructured data at any scale. Unlike traditional data storage methods, data lakes accept raw data in its native format without requiring preprocessing or schema definitions upfront. This raw data could include anything from logs, sensor data, and social media feeds, to multimedia content.
- The concept of a data lake contrasts with traditional data warehousing, where data is structured and organized before being stored, often resulting in data silos and limiting the types of data that can be stored or analyzed efficiently. Data lakes, on the other hand, embrace the concept of storing data in its raw form and processing it on demand when needed.
- Data lakes typically leverage scalable and distributed storage technologies such as Hadoop Distributed File System (HDFS), cloud storage solutions like Amazon S3 or Azure Data Lake Storage, or a combination. These technologies allow organizations to store massive amounts of data cost-effectively and efficiently.
Importance in Data Management:
- Flexibility: By accepting data in its raw form, data lakes provide flexibility in terms of data types and formats, enabling organizations to capture and store diverse datasets without worrying about schema design upfront.
- Scalability: With the ability to store petabytes of data, data lakes can scale horizontally to accommodate growing data volumes, making them suitable for storing big data generated from various sources.
- Cost-effectiveness: Compared to traditional data warehousing solutions, data lakes offer a more cost-effective approach to storing large volumes of data, especially with the availability of cloud-based storage options that provide pay-as-you-go pricing models.
- Advanced analytics: Data lakes serve as a foundation for performing advanced analytics, including machine learning, artificial intelligence, and data mining. By consolidating data from different sources into a single repository, organizations can derive valuable insights and make data-driven decisions.
- Data democratization: Data lakes promote data democratization by providing a central location where data is accessible to authorized users across the organization. This accessibility encourages collaboration and innovation by empowering users to explore and analyze data without relying on IT teams for data provisioning.
AWS Data Lake Fundamentals
Overview of AWS Services:
Amazon Web Services (AWS) is a comprehensive and widely-used cloud computing platform offered by Amazon.com. It provides a variety of services, including computing power, storage options, networking, databases, analytics, machine learning, and more. AWS allows businesses to scale and grow without the need for significant upfront investments in infrastructure.
Key Components of AWS Data Lake Architecture:
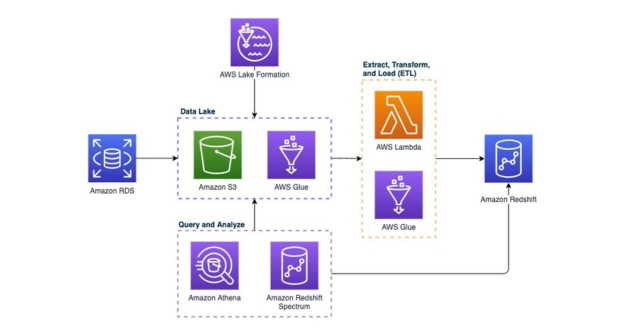
- Amazon S3 (Simple Storage Service):
Amazon S3 is an object storage service that offers scalability, durability, and security for storing data in the cloud. It allows users to store and retrieve any amount of data from anywhere on the web. S3 is often used as the foundational storage layer for data lakes due to its low cost, high availability, and seamless integration with other AWS services.
- AWS Glue:
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It automatically discovers, catalogs, and transforms metadata about your data assets stored on AWS. Glue can be used to clean, enrich, and normalize data before loading it into the data lake, helping to ensure that the data is accurate and consistent for analysis.
- Amazon Athena:
Amazon Athena is an interactive query service that allows users to analyze data directly in Amazon S3 using standard SQL. It eliminates the need to set up and manage infrastructure for querying data, as Athena automatically scales to handle any amount of data stored in S3. Athena is ideal for ad-hoc analysis and exploration of data stored in the data lake, enabling users to gain insights quickly and efficiently.
- Amazon Redshift Spectrum:
Amazon Redshift Spectrum is a feature of Amazon Redshift, a fully managed data warehouse service, that allows users to run queries directly against data stored in Amazon S3. Redshift Spectrum extends the capabilities of Redshift to analyze vast amounts of data in S3 without the need to load it into Redshift first. This enables organizations to leverage the power of Redshift for complex analytics while keeping frequently accessed data in S3 for cost-effective storage.
- AWS Lake Formation:
AWS Lake Formation is a service that simplifies the process of building, securing, and managing data lakes on AWS. It provides a central location for defining and enforcing data access policies, managing metadata, and configuring data ingestion workflows. Lake Formation automates many of the tasks involved in setting up a data lake, making it easier for organizations to get started with data lake projects and ensuring compliance with data governance standards.
Designing an AWS Data Lake
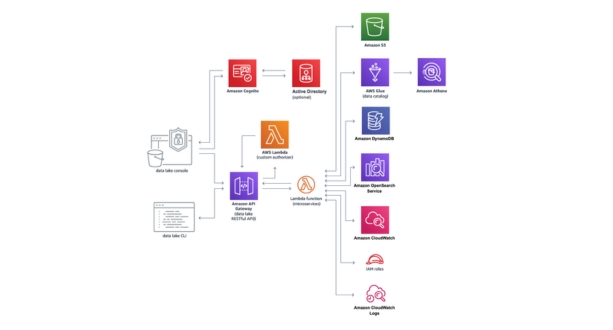
Planning and Requirements Gathering:
In this initial phase, the goals, objectives, and specific requirements of the data lake project are defined. This includes understanding the types of data to be ingested, the intended use cases, the expected volume and variety of data, compliance and regulatory requirements, budget constraints, and performance expectations. Stakeholder input is crucial during this phase to align the data lake design with business needs.
Architectural Considerations:
- Scalability:
Scalability is essential to accommodate the growing volume and variety of data over time. AWS provides scalable storage solutions such as Amazon S3, which can handle virtually unlimited amounts of data. Additionally, utilizing AWS services like Amazon EMR (Elastic MapReduce) for distributed data processing ensures that the data lake can scale horizontally to handle increased computational demands.
- Security:
Security is paramount when designing a data lake, especially considering the sensitive nature of the data stored within it. AWS offers a range of security features, including encryption at rest and in transit, identity and access management (IAM) controls, fine-grained access control policies using AWS IAM roles and policies, and integration with AWS Key Management Service (KMS) for managing encryption keys. Implementing these security measures helps protect data integrity and confidentiality within the data lake.
- Data Ingestion Strategies:
Data ingestion involves the process of collecting and loading data into the data lake. AWS offers various ingestion methods depending on the source and format of the data, including batch ingestion using AWS Glue for ETL (Extract, Transform, Load) workflows, real-time ingestion using services like Amazon Kinesis Data Streams or AWS Data Pipeline, and direct data transfer from on-premises systems using AWS Direct Connect or AWS Storage Gateway. Choosing the appropriate ingestion strategy depends on factors such as data volume, velocity, and latency requirements.
- Data Cataloging:
Data cataloging involves organizing and cataloging metadata to facilitate data discovery, governance, and self-service analytics. AWS provides services like AWS Glue Data Catalog, which automatically crawls and catalogs metadata from various data sources, making it easier to search, query, and analyze data within the data lake. Leveraging a centralized data catalog ensures that data consumers can easily find and understand the available datasets, leading to improved productivity and collaboration across teams.
- Data Processing Pipelines:
Data processing pipelines are workflows that transform and analyze data within the data lake to derive insights and value. AWS offers a range of services for building and orchestrating data processing pipelines, such as Amazon EMR for running distributed data processing frameworks like Apache Spark and Apache Hadoop, AWS Glue for serverless ETL, and AWS Lambda for event-driven processing. Designing efficient data processing pipelines involves considering factors such as data freshness, latency requirements, computational resources, and fault tolerance.
Implementing AWS Data Lake Solutions

Setting Up Amazon S3 Buckets:
Amazon Simple Storage Service (Amazon S3) is a widely used object storage service that provides highly scalable, durable, and secure storage. Setting up S3 buckets involves creating storage containers where you’ll store your data. These buckets can be organized to reflect your data lake architecture, with appropriate access controls and encryption settings applied to ensure data security and compliance.
Data Ingestion with AWS Glue:
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It allows you to crawl various data sources, infer schema, and automatically generate ETL code to transform and load the data into your data lake. With Glue, you can automate the ingestion process, handle schema evolution, and ensure data quality before storing it in S3.
Metadata Management and Cataloging:
Metadata management is crucial for understanding and effectively utilizing the data stored in the data lake. AWS provides services like AWS Glue Data Catalog for managing metadata, which includes information about the data schema, location, and other attributes. By cataloging metadata, you can easily discover, query, and analyze the data using various AWS services.
Querying Data with Amazon Athena:
Amazon Athena is an interactive query service that allows you to analyze data directly from Amazon S3 using standard SQL queries. It eliminates the need to set up and manage infrastructure, as Athena is serverless and automatically scales to handle any query workload. By leveraging Athena, you can quickly gain insights from your data lake without the need for complex data movement or transformation.
Optimizing Performance with Redshift Spectrum:
Amazon Redshift is a fully managed data warehouse service that allows you to run complex analytics queries on large datasets. Redshift Spectrum extends the querying capabilities of Redshift to data stored in S3, enabling you to analyze both structured and semi-structured data without having to load it into Redshift. By using Redshift Spectrum, you can optimize query performance and reduce costs by leveraging the scale and flexibility of S3 storage.
Best Practices and Tips
Data Partitioning and Organization:
- Data Partitioning: Divide your data into smaller, manageable chunks or partitions based on certain criteria such as date, region, or user. This helps improve query performance and scalability.
- Schema Design: Organize your data schema efficiently to optimize for query performance and data retrieval. This involves normalization, denormalization, and careful consideration of relationships between data entities.
- Data Lifecycle Management: Implement strategies for managing the lifecycle of your data, including archiving, backup, and deletion policies. This ensures that your data remains relevant and useful while minimizing storage costs.
- Metadata Management: Maintain comprehensive metadata about your data, including data lineage, data quality, and data usage information. This helps in understanding the context and history of your data, facilitating easier management and analysis.
Security and Access Control:
- Authentication and Authorization: Implement robust authentication mechanisms to ensure that only authorized users can access your data. This may involve using techniques such as multi-factor authentication (MFA) and role-based access control (RBAC).
- Encryption: Encrypt sensitive data both at rest and in transit to protect it from unauthorized access or interception. Use strong encryption algorithms and key management practices to safeguard your data.
- Data Masking and Anonymization: Apply techniques such as data masking and anonymization to protect sensitive information while still allowing for analysis and processing.
- Audit Logging: Enable comprehensive audit logging to track access to your data and monitor for suspicious activities or security breaches. This helps in compliance with regulatory requirements and identifying security incidents in real time.
Cost Optimization Strategies:

- Resource Sizing and Scaling: Right-size your resources to match your workload demands, avoiding over-provisioning and under-provisioning. Use auto-scaling capabilities to dynamically adjust resources based on usage patterns.
- Reserved Instances and Savings Plans: Take advantage of discounts offered by cloud providers through reserved instances or savings plans for predictable workloads.
- Storage Optimization: Optimize your storage usage by regularly cleaning up unused data, leveraging compression and deduplication techniques, and choosing cost-effective storage options such as object storage or cold storage.
- Cost Monitoring and Analysis: Continuously monitor your cloud usage and spending patterns, and analyze cost breakdowns to identify areas for optimization. Implement cost allocation tags and budgets to control spending and prevent cost overruns.
Monitoring and Maintenance:
- Performance Monitoring: Monitor key performance metrics such as latency, throughput, and resource utilization to ensure optimal system performance. Use monitoring tools and dashboards to visualize and analyze performance data in real time.
- Health Checks and Alerts: Implement automated health checks and set up alerts to notify you of any issues or anomalies in your system. This enables proactive maintenance and troubleshooting to minimize downtime.
- Patch Management: Keep your system up-to-date with the latest patches and security updates to address vulnerabilities and ensure system stability.
- Backup and Disaster Recovery: Establish robust backup and disaster recovery mechanisms to protect your data and applications against unexpected failures or disasters. Regularly test your backup and recovery processes to verify their effectiveness.
Challenges and Limitations
Data Governance and Compliance:
Data governance refers to the overall management of the availability, usability, integrity, and security of data used within an organization. Compliance, on the other hand, pertains to adhering to regulations, standards, and policies set forth by various governing bodies or industry best practices.
- Regulatory Compliance: Organizations must ensure that their data practices comply with legal requirements such as GDPR, CCPA, HIPAA, etc., depending on the nature of the data they handle and the regions they operate in.
- Data Security: Ensuring data security is crucial to prevent unauthorized access, data breaches, or leaks. This involves implementing robust access controls, encryption mechanisms, and data masking techniques.
- Data Quality: Maintaining high-quality data is essential for accurate decision-making. Data governance frameworks typically include processes for data validation, cleansing, and normalization.
- Data Lifecycle Management: Managing data throughout its lifecycle, from creation to archival or deletion, requires clear policies and procedures to avoid data redundancy, inconsistency, or retention beyond legal requirements.
- Cultural Challenges: Implementing data governance often requires a cultural shift within an organization to prioritize data management and compliance across all departments and levels.
Complexities in Integration:
Integration challenges arise when connecting various systems, applications, and data sources within an organization’s IT infrastructure to enable seamless data flow and business processes.
- Heterogeneous Systems: Organizations typically use a variety of systems and technologies, each with its own data formats, protocols, and interfaces, making integration complex and challenging.
- Data Silos: Data silos occur when information is isolated within specific departments, applications, or systems, hindering data visibility and accessibility across the organization.
- Real-Time Integration: The need for real-time data exchange between different systems and applications adds complexity, requiring robust integration middleware and technologies like APIs, ETL tools, or messaging queues.
- Scalability: As the volume and complexity of data increase, integration solutions must be scalable to handle growing data loads without compromising performance or reliability.
- Legacy Systems: Integrating legacy systems with modern applications or cloud platforms can be challenging due to compatibility issues, lack of APIs, or outdated technology stacks.
Performance Bottlenecks:
Performance bottlenecks refer to factors that degrade the speed or efficiency of data processing, storage, or retrieval within an IT system or application.
- Hardware Limitations: Inadequate hardware resources such as CPU, memory, or storage can lead to performance bottlenecks, especially when dealing with large volumes of data or complex computational tasks.
- Network Latency: Slow network connections or high latency can impact data transfer speeds, particularly in distributed systems or cloud environments where data is transmitted between geographically dispersed locations.
- Inefficient Algorithms: Poorly optimized algorithms or inefficient data processing techniques can significantly degrade system performance, leading to delays or timeouts in data processing pipelines.
- Concurrency Issues: Concurrent access to shared resources or data contention among multiple users or processes can lead to performance degradation or deadlock situations.
- Inadequate Indexing: In databases, inadequate indexing strategies or missing indexes can result in slow query performance, especially when dealing with large datasets or complex queries.
Conclusion
In conclusion, AWS Data Lake Solutions provide organizations with a powerful platform for managing, analyzing, and deriving insights from their data at scale. By offering scalability, flexibility, security, cost-effectiveness, analytics capabilities, ease of management, and seamless integration with the AWS ecosystem, these solutions empower organizations to unlock the full potential of their data and drive innovation across their business.
AWS Data Lake supports storing structured data (e.g., databases, tables) as well as unstructured data (e.g., log files, images, videos) in various formats including JSON, CSV, Parquet, and Avro.
Data can be ingested into AWS Data Lake using various methods such as batch uploads using AWS CLI or SDKs, streaming data using Amazon Kinesis, data replication using AWS DMS (Database Migration Service), and direct data transfer from on-premises using AWS Storage Gateway.
Yes, you can perform real-time analytics on data stored in AWS Data Lake using services like Amazon Kinesis Data Analytics or by integrating with streaming platforms like Apache Kafka.
AWS Data Lake pricing typically involves paying for the storage used in Amazon S3, data transfer costs, and fees for additional services such as AWS Glue and AWS Lake Formation. Pricing can vary based on data volume, storage class, and additional services utilized.
AWS Data Lake offers features for data governance such as data cataloging with AWS Glue, which provides a centralized metadata repository for managing data definitions, lineage, and access control policies. AWS Lake Formation also enables fine-grained access control and permissions management.


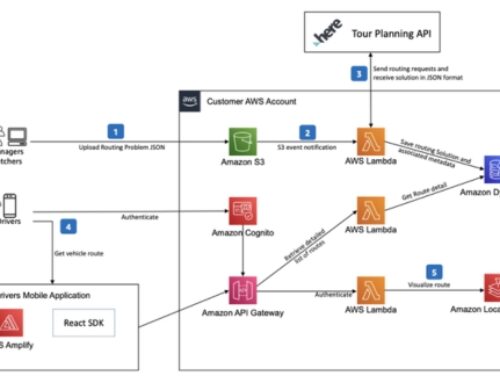


{kind=link}
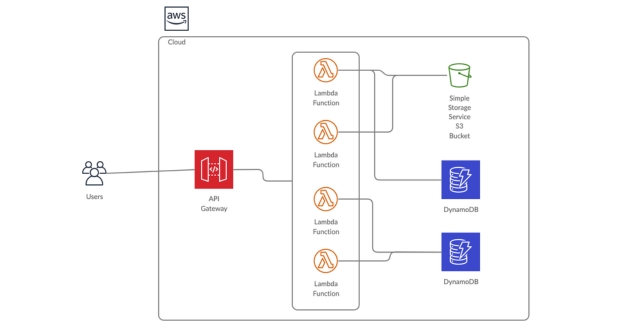
{kind=link}
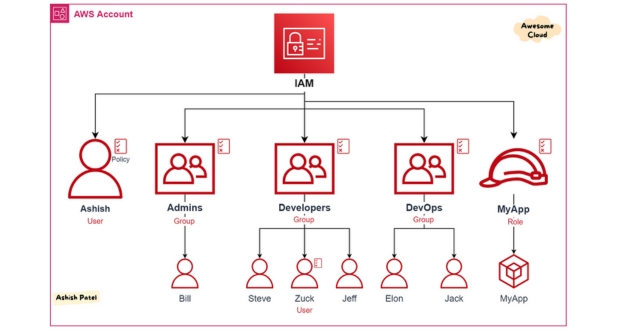
{kind=link}
{kind=link}
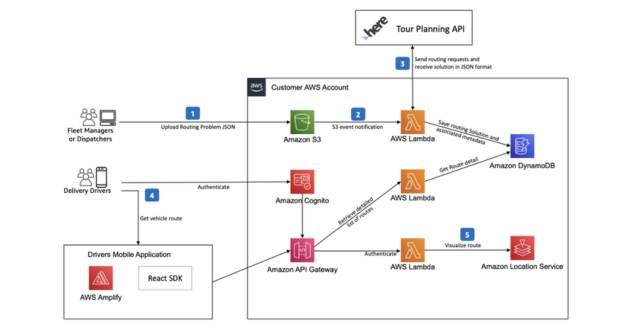{kind=link}