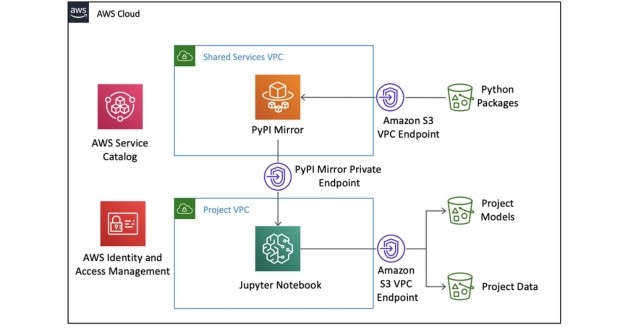
Introduction to AWS SageMaker:

Amazon SageMaker is a comprehensive machine learning (ML) service provided by Amazon Web Services (AWS). It aims to simplify the process of building, training, and deploying machine learning models at scale. SageMaker offers a wide range of tools and functionalities that cater to various stages of the machine learning lifecycle, from data preprocessing to model deployment and monitoring.
Overview of AWS SageMaker:
AWS SageMaker provides a unified platform that encompasses everything needed to develop and deploy machine learning models. Key components of SageMaker include:
Data Labeling and Preparation: SageMaker facilitates the preprocessing of data and provides tools for labeling datasets, an essential step in supervised learning tasks.
Model Training: SageMaker supports the training of machine learning models using built-in algorithms, custom algorithms, or pre-trained models. Users can choose from a variety of algorithms and frameworks, including TensorFlow, PyTorch, and Apache MXNet.
Model Tuning: SageMaker offers automated model tuning capabilities, allowing users to optimize hyperparameters and improve model performance without manual intervention.
Model Hosting: Once a model is trained, SageMaker enables easy deployment by providing hosting services. Models can be deployed as endpoints, making them accessible via APIs for real-time inference.
Model Monitoring and Management: SageMaker includes features for monitoring model performance and detecting drift in data distribution over time. It also provides tools for model versioning and management, simplifying the process of updating and maintaining deployed models.
Integration with Other AWS Services: SageMaker seamlessly integrates with other AWS services, such as S3 for data storage, AWS Lambda for serverless computing, and AWS Glue for data integration, enabling end-to-end machine learning workflows.
Importance of Machine Learning in Modern Business:
Machine learning plays a crucial role in modern businesses across various industries due to its ability to extract valuable insights from data and automate decision-making processes. Some key reasons why machine learning is important for businesses include:
Data-Driven Decision Making: Machine learning algorithms analyze large volumes of data to uncover patterns and trends that can inform strategic decision-making, leading to more informed and data-driven business strategies.
Personalization: Machine learning enables businesses to deliver personalized experiences to their customers by analyzing past behavior and preferences to make recommendations or tailor products and services accordingly.
Automation and Efficiency: Machine learning automates repetitive tasks and processes, improving operational efficiency and freeing up human resources to focus on more strategic initiatives.
Predictive Analytics: Machine learning models can forecast future trends and outcomes based on historical data, helping businesses anticipate demand, identify potential risks, and optimize resource allocation.
Competitive Advantage: Businesses that leverage machine learning effectively gain a competitive edge by extracting insights faster, adapting to changing market conditions more quickly, and delivering superior customer experiences.
Getting Started with SageMaker

Setting Up AWS Account and Accessing SageMaker:
- To begin with Amazon SageMaker, you first need to have an AWS (Amazon Web Services) account. If you don’t have one, you can sign up for an account on the AWS website.
- Once you have your AWS account set up, you can access SageMaker through the AWS Management Console. Simply navigate to the SageMaker service from the console.
- You’ll need to ensure that your IAM (Identity and Access Management) user or role has the necessary permissions to access SageMaker resources. AWS provides fine-grained control over access to services and resources through IAM policies.
Creating a Notebook Instance:
- In SageMaker, a notebook instance is where you can create and run Jupyter notebooks for data exploration, model training, and deployment.
- To create a notebook instance, you’ll navigate to the SageMaker console, select “Notebook instances,” and then click “Create notebook instance.”
- You’ll need to specify details such as the notebook instance name, instance type (which determines the compute resources available), and optionally, you can choose to encrypt the data stored on the notebook instance.
- Once you’ve configured the settings, you can create the notebook instance. It will take a few minutes to provision the resources.
- Once the instance is created, you can access the Jupyter notebook interface through your web browser. From there, you can create new notebooks, upload existing ones, and start working with your data and models.
Understanding SageMaker Studio:
- SageMaker Studio is an integrated development environment (IDE) provided by AWS for building, training, and deploying machine learning models.
- It provides a unified interface for data scientists, developers, and machine learning engineers to work collaboratively on machine learning projects.
- SageMaker Studio includes a variety of features such as Jupyter notebooks, data exploration tools, debugging and profiling tools, experiment tracking, model debugging, and automated model tuning.
- With SageMaker Studio, you can manage the entire machine learning workflow from data preparation to model deployment in a single environment, making it easier to iterate on models and collaborate with team members.
- To access SageMaker Studio, you can navigate to the SageMaker console and select “SageMaker Studio” from the menu. From there, you can launch Studio and start working on your projects.
Data Preparation and Preprocessing
Data preparation and preprocessing are crucial steps in any data science or machine learning project. They involve getting the data ready for analysis and modeling by cleaning, transforming, and structuring it appropriately.
Data Preparation: This involves gathering data from various sources and formats, such as databases, spreadsheets, APIs, or files like CSV or JSON. Data may come with missing values, outliers, or inconsistencies that need to be addressed before further analysis. Data preparation tasks include data collection, integration, cleaning, and transformation.
Importing Data into SageMaker: Amazon SageMaker is a cloud machine learning platform provided by Amazon Web Services (AWS). Importing data into SageMaker involves uploading the dataset to an AWS S3 bucket or directly accessing data stored in other AWS services like Amazon RDS or Amazon Redshift. SageMaker provides APIs and SDKs for various programming languages (such as Python) to facilitate this process.
Exploratory Data Analysis (EDA) Tools: EDA is the process of analyzing data sets to summarize their main characteristics, often using visual methods. EDA helps to understand the structure and distribution of the data, identify patterns, detect outliers, and formulate hypotheses for further investigation. Common EDA tools include statistical summaries, histograms, scatter plots, box plots, and correlation matrices.
Data Cleaning: Data cleaning involves handling missing values, dealing with outliers, correcting errors, and ensuring consistency in the data. Techniques for data cleaning include imputation (replacing missing values with estimated values), outlier detection and removal, data normalization or scaling, and handling duplicates or inconsistencies.
Data Transformation Techniques: Data transformation prepares the data for modeling by converting it into a format suitable for analysis and machine learning algorithms. This may involve feature engineering, where new features are created from existing ones, such as combining or transforming variables, encoding categorical variables, and scaling or standardizing numerical features. Dimensionality reduction techniques like PCA (Principal Component Analysis) or feature selection methods may also be applied to reduce the complexity of the data while preserving its essential information.
Model Development and Training
Choosing the Right Algorithm:
This step involves selecting the appropriate machine learning algorithm that best suits the problem at hand and the nature of the dataset. There are various types of algorithms such as supervised learning (e.g., regression, classification), unsupervised learning (e.g., clustering, dimensionality reduction), and reinforcement learning. The choice depends on factors like the type of data available, the complexity of the problem, and the desired outcome.
Hyperparameter Optimization:
Once the algorithm is selected, hyperparameter optimization comes into play. Hyperparameters are parameters that are set before the learning process begins. They govern the learning process’s behavior and directly impact the performance of the model. Techniques such as grid search, random search, and more advanced methods like Bayesian optimization or genetic algorithms are used to systematically explore the hyperparameter space and find the optimal set of hyperparameters that maximize the model’s performance on a validation dataset.
Training Models at Scale:
As datasets grow larger and more complex, training models at scale becomes necessary. This involves utilizing distributed computing frameworks and specialized hardware accelerators (like GPUs and TPUs) to efficiently train models on vast amounts of data. Techniques such as data parallelism and model parallelism are employed to distribute the training workload across multiple machines or devices. Additionally, platforms like TensorFlow, PyTorch, and Apache Spark provide tools and libraries for distributed training, enabling practitioners to train large-scale models effectively.
Model Deployment and Management
Deploying Models with SageMaker Endpoints:
Amazon SageMaker is a fully managed service provided by Amazon Web Services (AWS) that enables developers and data scientists to build, train, and deploy ML models at scale. SageMaker provides an easy way to deploy models through endpoints, which are HTTPS URLs that can be used to send data to a deployed model and receive predictions in return. SageMaker endpoints handle the deployment infrastructure, scaling, and load balancing, allowing users to focus on model development rather than managing the deployment environment.
Monitoring Model Performance:
Once a model is deployed, it’s essential to monitor its performance in real-time to ensure that it continues to perform accurately and efficiently. Monitoring model performance involves tracking various metrics such as inference latency, throughput, error rates, and resource utilization. By monitoring these metrics, developers can identify issues such as degraded performance, drift in data distribution, or changes in model behavior over time. Monitoring tools integrated with SageMaker or external monitoring systems can provide insights into model performance and help teams maintain the reliability and effectiveness of deployed models.
Updating and Versioning Models:
ML models are not static entities; they often require updates to improve performance, accommodate changes in data distributions, or address new business requirements. SageMaker facilitates model versioning, allowing users to create multiple versions of a model and deploy them independently. This enables seamless updates to models without disrupting production workflows. Versioning also provides a way to roll back to previous model versions if new versions introduce unexpected issues. Additionally, SageMaker supports automated model retraining and deployment pipelines, streamlining the process of updating models in response to changing conditions or feedback from monitoring systems.
Deploying and managing ML models with SageMaker involves deploying models using endpoints, monitoring their performance in real-time, and managing model versions to facilitate updates and ensure continuous improvement in production environments. SageMaker’s integrated tools and services simplify these tasks, enabling organizations to deploy and maintain ML models efficiently and effectively.
SageMaker Autopilot
Amazon SageMaker Autopilot is a fully managed service provided by Amazon Web Services (AWS) that automates the process of building, training, and deploying machine learning models. It is designed to make machine learning more accessible to developers, data scientists, and other professionals by reducing the complexities involved in model selection, feature engineering, and hyperparameter tuning.
Introduction to SageMaker Autopilot:

SageMaker Autopilot simplifies the machine learning workflow by automating several tedious and time-consuming tasks.
It starts with analyzing your dataset to understand its characteristics, such as the types of features, missing values, and distribution of data.
Based on this analysis, Autopilot selects appropriate preprocessing techniques, feature transformations, and algorithms to build the best-performing model.
Using Autopilot for Model Selection and Tuning:
Autopilot employs a variety of algorithms and techniques, including tree-based models, linear models, and deep learning, to explore the dataset and identify the most suitable model architecture.
It automatically tunes hyperparameters such as learning rates, regularization parameters, and tree depths to optimize model performance.
Autopilot also conducts extensive experimentation to find the optimal combination of preprocessing steps and feature engineering techniques.
Customizing Autopilot Jobs:
While Autopilot automates much of the machine learning process, users have the flexibility to customize certain aspects of the job.
For example, users can specify constraints on the resources allocated to the Autopilot job, such as the maximum training time or the instance type.
Users can also provide input on the type of problem they are trying to solve (e.g., regression, classification) and any domain-specific knowledge that may guide the model selection process.
SageMaker Marketplace:
- The SageMaker Marketplace is an online store where users can discover, buy, and deploy machine learning algorithms, models, and other related tools. These offerings are provided by both AWS and third-party vendors.
- Users can explore a wide range of pre-built models and algorithms, covering various use cases such as natural language processing, computer vision, time series analysis, and more.
- The marketplace offers both free and paid listings, allowing users to choose solutions that best fit their requirements and budget.
- By leveraging pre-built models from the marketplace, users can accelerate the development of their machine learning projects, reduce time-to-market, and potentially save on development costs.
Exploring Pre-built Models and Algorithms:
- Within the SageMaker Marketplace, users can explore a diverse selection of pre-built models and algorithms tailored for different tasks and industries.
- These pre-built solutions are typically trained on large datasets and optimized for performance and accuracy, making them suitable for various machine learning applications.
- Users can browse through available offerings, evaluate their performance through documentation and sample code, and select the most suitable model or algorithm for their specific use case.
- The availability of pre-built models reduces the need for users to build and train models from scratch, enabling faster prototyping and deployment of machine learning applications.
Extending SageMaker Functionality with Third-party Extensions:
- SageMaker Extensions allow users to extend the functionality of SageMaker by integrating third-party tools, libraries, and frameworks.
- These extensions enable users to incorporate additional features and capabilities into their machine learning workflows, beyond what is provided by the core SageMaker service.
- Examples of third-party extensions may include custom data processing libraries, specialized optimization algorithms, model interpretability tools, or integration with external data sources.
- By integrating third-party extensions, users can tailor Sage Maker to their specific requirements, leverage niche functionalities, and seamlessly integrate with their existing machine learning ecosystem.
Security and Compliance Considerations
AWS Identity and Access Management (IAM) Roles:
IAM roles in AWS are used to manage permissions for different entities within your AWS environment, such as users, applications, or services. These roles define what actions these entities are allowed to perform on AWS resources. When designing security in AWS, it’s crucial to properly configure IAM roles to ensure that only authorized entities have access to sensitive resources and that the principle of least privilege is enforced. This means granting only the permissions necessary for entities to perform their intended tasks, reducing the risk of unauthorized access or accidental misuse.
Data Encryption and Access Controls:
Data encryption is essential for protecting sensitive information from unauthorized access or interception. In AWS, various encryption options are available for both data at rest and data in transit. For data at rest, you can use services like AWS Key Management Service (KMS) to manage encryption keys and encrypt data stored in Amazon S3, EBS volumes, RDS databases, etc. For data in transit, you can enable encryption protocols such as SSL/TLS for communication between AWS services or between your applications and AWS services. Access controls further enhance security by allowing you to restrict access to encrypted data only to authorized entities through mechanisms like IAM policies, bucket policies, or database permissions.
Compliance with Regulatory Standards:
Compliance with regulatory standards is critical for organizations operating in various industries, such as finance, healthcare, or government, where strict regulations govern the handling and protection of sensitive data. AWS provides a wide range of compliance certifications and assurance programs, including SOC, PCI DSS, HIPAA, GDPR, and many others, to help customers meet their compliance requirements. However, achieving compliance involves more than just using compliant services; it also requires implementing appropriate security controls, auditing processes, and documentation to demonstrate compliance with specific regulatory requirements. AWS provides tools and resources to help customers understand their compliance obligations and design architectures that meet those requirements while leveraging the security features and best practices of the AWS platform.
Cost Optimization Strategies:
These encompass a range of techniques and methodologies aimed at reducing costs across different aspects of operations. This might involve renegotiating contracts with suppliers for better rates, streamlining processes to eliminate waste, or investing in technologies that automate tasks to reduce labor costs. Cost optimization strategies can also involve evaluating alternative vendors or solutions to find the most cost-effective option without sacrificing quality.
Understanding Pricing Models:
Different services and products come with various pricing models, such as pay-as-you-go, subscription-based, or tiered pricing. Understanding these models is crucial for businesses to choose the most cost-effective option based on their usage patterns and requirements. For instance, if a company’s workload is relatively consistent, a fixed pricing model might be more cost-effective than a pay-as-you-go model.
Resource Allocation Best Practices:
Resource allocation involves distributing resources such as manpower, time, and budget effectively to achieve organizational objectives. Best practices in resource allocation include prioritizing projects based on their strategic importance and potential return on investment, leveraging cross-functional teams to optimize resource utilization, and regularly reviewing and adjusting allocations to align with changing business needs.
Cost Monitoring and Optimization Tools:
Utilizing tools and technologies designed for cost monitoring and optimization is essential for maintaining visibility into expenditure and identifying areas for improvement. These tools may include cloud cost management platforms, budgeting and forecasting software, and expense tracking solutions. By leveraging data analytics and reporting features offered by these tools, organizations can gain insights into their spending patterns and make informed decisions to optimize costs.
Conclusion:
In conclusion, AWS SageMaker represents a comprehensive platform for machine learning, offering a wide range of tools and services to streamline the end-to-end machine learning workflow. From data preparation and model development to deployment and management, SageMaker simplifies the complexities of machine learning, enabling organizations to leverage the power of AI effectively.
SageMaker consists of several key components including Jupyter notebooks for data exploration and model development, built-in algorithms for training models, model hosting for deployment, and monitoring tools for managing deployed models.
SageMaker simplifies the machine learning process by providing pre-built algorithms, managed infrastructure for training and deployment, automatic model tuning, and integrated development environments (IDEs) for data analysis and model building.
SageMaker supports a wide range of machine learning algorithms including linear regression, logistic regression, XGBoost, k-means clustering, random forests, deep learning (via TensorFlow or Apache MXNet), and many others.
Yes, SageMaker allows you to bring your own algorithms by packaging them in Docker containers and deploying them on SageMaker’s managed infrastructure.
SageMaker provides built-in capabilities for data preprocessing and feature engineering, including data cleaning, normalization, feature transformation, and feature selection.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}