Introducing Amazon Redshift

Amazon Redshift is a fully managed, petabyte-scale data warehouse service provided by Amazon Web Services (AWS). It is designed to handle large-scale data analytics workloads, making it easier and more cost-effective for businesses to analyze vast amounts of data quickly and efficiently. Here’s a more detailed overview of Amazon Redshift and its various aspects:
Overview of Amazon Redshift and its Place in the AWS Ecosystem:
Amazon Redshift is a key component of AWS’s data analytics offerings. It allows users to run complex SQL queries against large datasets stored in a distributed and scalable manner. With Redshift, organizations can analyze data from various sources to derive insights for decision-making, reporting, and forecasting purposes. It integrates seamlessly with other AWS services, such as Amazon S3 for data storage, AWS Glue for data ingestion and transformation, and Amazon QuickSight for data visualization.
Evolution of Redshift and its Key Milestones:
Amazon Redshift has undergone significant evolution since its launch. Over the years, AWS has continuously enhanced its performance, scalability, and ease of use. Key milestones in the evolution of Redshift include improvements in query optimization, support for new data types and compression techniques, introduction of features like Spectrum for querying data directly from S3, and integration with machine learning services for advanced analytics.
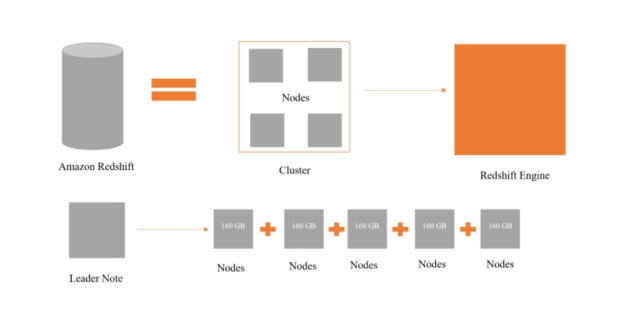
Architecture of Redshift: Cluster, Nodes, and Storage Layers:
Amazon Redshift operates on a distributed architecture that consists of clusters, nodes, and storage layers. A Redshift cluster is composed of multiple nodes, each of which is an individual compute unit with CPU, memory, and storage resources. Nodes are grouped into a leader node, which manages query execution and optimization, and compute nodes, which process data and execute queries in parallel. The storage layer uses columnar storage and massively parallel processing (MPP) to efficiently store and retrieve data across nodes.
Comparison with Traditional Data Warehousing Solutions:
Compared to traditional data warehousing solutions, such as on-premises databases or legacy data warehouses, Amazon Redshift offers several advantages. These include scalability, as Redshift can easily scale up or down to accommodate changing workloads and data volumes without requiring manual intervention. Redshift also provides high performance for analytical queries through its MPP architecture and columnar storage format. Additionally, Redshift is fully managed by AWS, eliminating the need for customers to manage infrastructure, backups, and maintenance tasks, which can reduce operational overhead and costs.
Amazon Redshift is a powerful data warehousing solution that enables organizations to analyze large volumes of data efficiently and cost-effectively. Its scalable architecture, integration with AWS services, and ease of management make it a popular choice for businesses seeking to derive insights from their data.
Understanding Data Warehousing
Data warehousing is a crucial concept in the field of data management and analytics, designed to help organizations store, manage, and analyze large volumes of structured and unstructured data from various sources. Here’s a more detailed explanation of the points you mentioned:
Definition and Importance of Data Warehousing:
- Data warehousing involves the process of collecting, storing, and managing data from various sources into a centralized repository, known as a data warehouse. This repository is optimized for querying and analysis, making it easier for businesses to derive insights and make informed decisions.
- The importance of data warehousing lies in its ability to provide a unified view of an organization’s data, enabling stakeholders to access consistent and reliable information for reporting, analysis, and decision-making purposes. By consolidating data from disparate sources, data warehousing helps organizations gain actionable insights and maintain a competitive edge in their respective industries.
Evolution of Data Warehousing Technologies:
- Data warehousing technologies have evolved significantly over the years, driven by advancements in computing, storage, and data processing capabilities. Initially, data warehouses were built using traditional relational database management systems (RDBMS).
- However, with the exponential growth of data volumes and the need for more sophisticated analytics, newer technologies such as columnar databases, massively parallel processing (MPP) systems, and cloud-based data warehouses have emerged. These technologies offer improved performance, scalability, and flexibility, allowing organizations to handle large-scale data analytics efficiently.
Key Components and Characteristics of a Data Warehouse:
A data warehouse typically consists of several key components, including:
Extraction, Transformation, and Loading (ETL) tools for extracting data from source systems, transforming it into a consistent format, and loading it into the data warehouse.
Data storage, which may involve relational databases, columnar databases, or distributed file systems depending on the architecture.
Metadata repository for storing information about the data stored in the warehouse, including its structure, lineage, and usage.
Query and reporting tools for analyzing data and generating insights through interactive dashboards, ad-hoc queries, and predefined reports.
Characteristics of a data warehouse include:
Subject-oriented: Organized around specific business subjects or areas, such as sales, finance, or customer data.
Integrated: Consolidates data from multiple sources to provide a unified view of the organization.
Time-variant: Stores historical data to support trend analysis, forecasting, and decision-making over time.
Non-volatile: Data in the warehouse is read-only and does not change frequently, ensuring consistency and reliability for analytical purposes.
Challenges Associated with Traditional Data Warehousing Solutions:
Traditional data warehousing solutions often face challenges related to scalability, performance, and agility. As data volumes continue to grow exponentially, maintaining and scaling traditional data warehouses can become costly and complex.
Additionally, integrating data from diverse sources with different formats and structures can be time-consuming and error-prone, leading to inconsistencies and inaccuracies in the warehouse.
Traditional data warehousing architectures may struggle to keep pace with the real-time data processing requirements of modern businesses, limiting their ability to deliver timely insights and support agile decision-making.
Features and Capabilities
Scalability:
Redshift offers both horizontal and vertical scaling options. Horizontal scaling involves adding more nodes to your Redshift cluster, allowing you to handle larger volumes of data and more concurrent queries. Vertical scaling involves upgrading the instance types of existing nodes in your cluster, providing more compute and memory resources.
Performance:
Redshift achieves high performance through various means. Columnar storage allows for efficient compression and retrieval of data by storing columns of data together rather than rows. Massively Parallel Processing (MPP) architecture divides data and query processing tasks across multiple nodes in a cluster, enabling parallel execution of queries for faster results. Additionally, Redshift employs query optimization techniques to enhance performance further.
Data ingestion:
Redshift provides multiple options for loading data into the database from various sources such as Amazon S3, Amazon DynamoDB, Amazon Kinesis, or other relational databases. This flexibility in data ingestion allows users to seamlessly integrate data from different systems into Redshift for analysis and reporting.
Integration with other AWS services:

Redshift integrates well with other AWS services such as Amazon S3 for data storage, AWS Glue for data cataloging and ETL (Extract, Transform, Load) jobs, AWS Lambda for serverless computing, among others. This integration facilitates a comprehensive data pipeline within the AWS ecosystem, enabling smooth data processing workflows.
Security and compliance features:
Redshift offers robust security features to protect sensitive data. This includes encryption of data at rest and in transit, integration with AWS Identity and Access Management (IAM) for managing user access and permissions, and audit logging for tracking user activity and compliance with regulatory requirements such as GDPR or HIPAA.
Monitoring and management:
Redshift provides tools for monitoring and managing clusters effectively. CloudWatch metrics allow users to monitor cluster performance and health in real-time, enabling proactive optimization and troubleshooting. Automated backups and maintenance tasks ensure data durability and cluster availability without manual intervention, reducing administrative overhead.
Best Practices for Redshift Implementation
Data Modeling:
- Star Schema vs. Snowflake Schema: Redshift supports both star and snowflake schema designs. Star schema is simpler and more denormalized, typically featuring a central fact table surrounded by dimension tables. Snowflake schema, on the other hand, normalizes dimension tables further, potentially improving data integrity but increasing complexity.
- Denormalization and Optimization Techniques: Denormalization can improve query performance by reducing the need for joins, but it requires careful consideration to avoid redundancy and maintain data consistency. Optimization techniques include selecting appropriate data types, indexing frequently queried columns, and optimizing table distribution and sort keys.
Workload Management (WLM):
- WLM Queues: Redshift’s Workload Management allows you to define queues and assign queries to specific queues based on priority or resource requirements. Properly configuring WLM queues ensures efficient resource allocation and query execution.
- Query Prioritization: Prioritizing critical queries over less important ones ensures that essential business operations are not disrupted by resource-intensive or long-running queries.
- Concurrency Scaling: Redshift’s concurrency scaling feature automatically adds additional cluster capacity to handle an increased number of concurrent queries, improving performance during peak usage periods.
Data Loading Strategies:
- Batch vs. Streaming: Batch loading involves periodically loading large volumes of data into Redshift using tools like AWS Data Pipeline or AWS Glue. Streaming involves real-time or near-real-time data ingestion using services like Amazon Kinesis Firehose or AWS Lambda.
- COPY Command Options: The COPY command efficiently loads data into Redshift from various data sources such as Amazon S3, DynamoDB, or even from remote hosts. Options like specifying data formats, delimiters, and error handling parameters optimize the loading process.
- Data Compression: Redshift supports various compression techniques like LZO, Zstandard, or Run-length encoding, which reduce storage space and improve query performance by minimizing disk I/O.
Performance Tuning:
- Distribution Styles: Choosing an appropriate distribution style (e.g., KEY, ALL, EVEN) for tables ensures even data distribution across cluster nodes, reducing data movement during query execution.
- Sort Keys: Defining sort keys on frequently queried columns improves query performance by minimizing the need for data sorting during query execution.
- Vacuuming: Regularly running the VACUUM command reclaims space and reorganizes data, improving query performance and reducing storage costs.
Cost Optimization:
- Right-Sizing Clusters: Adjusting the cluster size based on workload requirements ensures optimal performance while minimizing costs. Rightsizing involves selecting the appropriate node type and number of nodes.
- Reserved Instances: Purchasing reserved instances for predictable workloads can significantly reduce costs compared to on-demand pricing.
- Usage Analysis: Regularly monitoring and analyzing Redshift usage patterns and resource utilization helps identify opportunities for optimizing costs, such as identifying underutilized resources or inefficient queries.
Real-world Use Cases
Analytics and Reporting:
- Business Intelligence (BI): Data analytics tools are utilized to extract insights from vast amounts of data, enabling businesses to make informed decisions. This includes tracking key performance indicators (KPIs), monitoring sales trends, and assessing overall business health.
- Dashboards: Interactive visual representations of data that provide a snapshot of key metrics and trends. Dashboards allow stakeholders to quickly understand complex data and make timely decisions.
- Ad-hoc Queries: On-demand data queries that allow users to retrieve specific information from a database or data warehouse. Ad-hoc queries facilitate exploratory analysis and answer specific business questions.
Customer Segmentation and Targeting:
- Personalization: Leveraging customer data to tailor products, services, and marketing efforts to individual preferences and behaviors. Personalization enhances customer satisfaction, engagement, and loyalty.
- Marketing Campaigns: Analyzing customer demographics, behavior, and purchase history to design targeted marketing campaigns. This includes segmentation based on factors such as age, gender, location, and interests.
- Predictive Analytics: Utilizing machine learning algorithms to forecast future customer behavior, such as likelihood to purchase, churn, or respond to marketing initiatives.
Log Analysis and Monitoring:
- Operational Insights: Analyzing logs generated by systems, applications, and network devices to monitor performance, detect errors, and optimize operations. Log analysis helps identify patterns, anomalies, and potential security threats.
- Anomaly Detection: Using statistical techniques and machine learning algorithms to identify deviations from expected behavior in log data. Anomaly detection aids in detecting security breaches, system failures, and operational inefficiencies.
- Troubleshooting: Investigating and resolving issues by analyzing log data to pinpoint the root cause of problems. Troubleshooting involves correlating events, identifying patterns, and implementing corrective actions.
Time-Series Data Analysis:

- Internet of Things (IoT): Analyzing data generated by IoT devices, such as sensors, wearables, and connected appliances. Time-series analysis of IoT data enables monitoring, predictive maintenance, and optimization of IoT deployments.
- Sensor Data: Analyzing time-stamped data collected from sensors in various domains, including manufacturing, healthcare, and environmental monitoring. Sensor data analysis facilitates real-time decision-making and proactive intervention.
- Financial Markets: Analyzing historical and real-time financial data, such as stock prices, exchange rates, and trading volumes. Time-series analysis in financial markets helps identify trends, forecast market movements, and inform investment strategies.
Data Science and Machine Learning:
- Model Training: Developing predictive models using machine learning algorithms to analyze data and make predictions. Model training involves selecting appropriate algorithms, preprocessing data, and optimizing model performance.
- Feature Engineering: Extracting and selecting relevant features from raw data to improve the performance of machine learning models. Feature engineering involves transforming data, creating new features, and reducing dimensionality.
- Inference: Applying trained machine learning models to new data to make predictions or classifications. Inference involves deploying models in production environments, handling real-time data streams, and monitoring model performance.
Case Studies of Organizations Leveraging Amazon Redshift:
Many organizations across various industries have successfully adopted Amazon Redshift to harness the power of their data. These case studies typically highlight how companies have used Redshift to streamline their data analytics processes, improve data accessibility, and gain deeper insights into their operations.
For example, a retail company might use Amazon Redshift to analyze customer purchasing patterns and optimize inventory management, while a healthcare organization could utilize it to analyze patient data for improving treatment outcomes and operational efficiency.
Lessons Learned and Best Practices Adopted by Leading Enterprises:
As organizations implement Amazon Redshift, they often encounter challenges and learn valuable lessons along the way. These lessons learned and best practices adopted by leading enterprises are crucial for other organizations considering or in the process of implementing Redshift.
Best practices may include optimizing data loading and query performance, designing efficient data schemas, managing security and access control, and integrating Redshift with other AWS services or third-party tools.
Impact on Business Outcomes: Increased Revenue, Cost Savings, and
Competitive Advantage:
The primary goal of leveraging Amazon Redshift is to drive positive business outcomes. By analyzing data more effectively and gaining actionable insights, organizations can make data-driven decisions that lead to increased revenue, cost savings, and competitive advantage.
For instance, a company might use Redshift to analyze sales data and identify high-value customers, leading to targeted marketing campaigns and increased sales revenue. Additionally, by optimizing operational processes through data analysis, organizations can achieve cost savings and improve overall efficiency, further enhancing their competitive position in the market.
Future Trends and Innovations
Advances in Cloud Data Warehousing:
- Serverless Architectures: Cloud data warehousing is evolving towards serverless architectures, where users don’t need to manage the infrastructure. This approach offers benefits such as auto-scaling, reduced operational overhead, and cost optimization.
- Multi-Cloud Deployments: Companies are increasingly adopting multi-cloud strategies to avoid vendor lock-in and enhance resilience. Cloud data warehousing solutions are adapting to this trend by offering seamless integration and management across multiple cloud providers.
- AI-Driven Analytics: Integrating artificial intelligence (AI) and machine learning (ML) capabilities into data warehousing solutions enables advanced analytics, predictive modeling, and automated insights generation. These AI-driven analytics empower organizations to derive valuable insights from their data more efficiently.
Integration with Emerging Technologies:
- Blockchain: Integrating blockchain technology with data warehousing can enhance data security, integrity, and transparency. By providing immutable ledgers and decentralized data storage, blockchain complements data warehousing solutions, especially in industries like finance, supply chain, and healthcare.
- Edge Computing: Edge computing brings computation and data storage closer to the data source, reducing latency and bandwidth usage. Integrating data warehousing with edge computing enables real-time analytics and decision-making at the edge, benefiting use cases like IoT, autonomous vehicles, and manufacturing.
- Quantum Computing: While still in its nascent stages, quantum computing holds the promise of revolutionizing data processing and analysis. Integrating data warehousing with quantum computing technologies can potentially unlock unprecedented computational power, enabling complex analytics and simulations at scale.
Evolution of Redshift:
- New Features: Amazon Redshift, a popular cloud data warehousing solution, continues to evolve with the introduction of new features and functionalities. These may include improvements in data ingestion, query performance, data security, and management tools.
- Performance Enhancements: Redshift is likely to receive performance enhancements through optimizations in query execution, parallel processing, and data compression techniques. These enhancements aim to improve query response times and overall system throughput.
- Ecosystem Partnerships: Redshift’s ecosystem is expanding through partnerships with third-party vendors and integration with complementary services. These partnerships enable users to leverage additional tools, connectors, and extensions to enhance their data warehousing workflows and analytics capabilities.
Conclusion
Amazon Redshift has emerged as a game-changer in the realm of data warehousing, offering unmatched scalability, performance, and flexibility to organizations of all sizes. By harnessing the power of Redshift, enterprises can unlock the full potential of their data, driving innovation, efficiency, and growth. As we continue to witness rapid advancements in cloud technology and data analytics, Redshift is poised to remain at the forefront, empowering businesses to thrive in the data-driven era.
Some key benefits include scalability to petabyte-scale data volumes, high performance for complex queries, ease of use with SQL-based interfaces, integration with other AWS services, and cost-effectiveness with pay-as-you-go pricing.
AWS Redshift is optimized for analytical workloads, such as data warehousing, business intelligence, reporting, and data analysis. It is less suitable for transactional or operational workloads.
AWS Redshift pricing is based on factors like the size and number of nodes in your cluster, the amount of data transferred, and any additional features or services used. You typically pay for compute and storage separately, with options for on-demand or reserved pricing.
Yes, AWS Redshift is compatible with a wide range of BI and analytics tools, including popular ones like Tableau, Looker, Power BI, and more. It supports standard SQL interfaces, JDBC, and ODBC connections for easy integration.
Data can be ingested into Redshift from various sources, including Amazon S3, Amazon DynamoDB, Amazon RDS, and other databases. You can use tools like AWS Glue, AWS Data Pipeline, or custom ETL (Extract, Transform, Load) processes to load data into Redshift.



{kind=link}
{kind=link}
{kind=link}
{kind=link}