Understanding High Availability Architecture
High Availability (HA) Architecture refers to the design and implementation of systems or services that are continuously operational and accessible, often with minimal downtime or disruption.
What is High Availability?
High Availability (HA) refers to the ability of a system or service to remain operational and accessible for users, typically aiming for a very high uptime percentage. This means that even in the event of hardware failures, software failures, or other disruptions, the system can quickly recover and continue to function without significant impact on users.
Importance of High Availability in Modern Computing
High Availability is crucial in modern computing environments due to the increasing reliance on digital services and applications. Downtime or service interruptions can lead to significant financial losses, damage to reputation, and loss of productivity. In industries such as e-commerce, finance, healthcare, and telecommunications, where continuous availability is critical, HA architecture is essential to ensure uninterrupted service delivery.
AWS’s Role in High Availability

Amazon Web Services (AWS) provides a range of services and features that support High Availability architectures. AWS offers tools for redundancy, load balancing, auto-scaling, data replication, and geographic distribution, allowing organizations to design and deploy highly available systems across multiple regions and availability zones. AWS also provides managed services like Amazon RDS (Relational Database Service), Amazon S3 (Simple Storage Service), and Amazon DynamoDB, which are inherently designed for high availability.
Key Concepts: Fault Tolerance vs. High Availability
Fault Tolerance and High Availability are related concepts but with subtle differences:
Fault Tolerance refers to a system’s ability to continue operating even when one or more components fail. It often involves redundant components and mechanisms such as failover systems or mirroring to ensure continuous operation.
High Availability, on the other hand, focuses on ensuring that a system is always available and accessible to users, typically by minimizing downtime and ensuring rapid recovery in case of failures. While fault tolerance is a component of high availability, HA encompasses a broader set of strategies and technologies to achieve uninterrupted service delivery.
Principles of AWS High Availability Architecture

Redundancy: The Backbone of High Availability
Redundancy in AWS high availability architecture refers to the duplication of critical components to ensure that if one fails, another can seamlessly take its place without causing downtime or disruption to services. This redundancy can be implemented at various levels, including within data centers, across availability zones, and even across regions. For example, AWS offers services like Amazon S3 for data storage, which automatically replicates data across multiple facilities within a region, providing built-in redundancy. Additionally, services like Amazon EC2 Auto Scaling can help ensure redundancy by automatically launching new instances to replace failed ones.
Scalability: Meeting Demand Fluctuations
Scalability is essential for accommodating varying levels of demand without compromising performance or availability. AWS provides various tools and services to help businesses scale their infrastructure dynamically. For example, Amazon EC2 Auto Scaling allows you to automatically adjust the number of EC2 instances based on demand, ensuring that you have enough capacity to handle increased traffic during peak times. Similarly, services like Amazon RDS (Relational Database Service) offer automated scaling capabilities to handle database workloads efficiently.
Automation: Reducing Manual Intervention
Automation plays a crucial role in maintaining high availability by reducing the need for manual intervention and minimizing the risk of human error. AWS offers a wide range of automation tools and services, such as AWS CloudFormation for infrastructure as code, AWS Lambda for serverless computing, and AWS Elastic Beanstalk for deploying and managing applications automatically. By automating tasks like deployment, scaling, and recovery, businesses can streamline operations and improve overall reliability.
Monitoring: Proactive Detection and Response
Effective monitoring is essential for identifying potential issues before they impact availability and performance. AWS provides various monitoring and logging services, such as Amazon CloudWatch, which allows you to monitor metrics, set alarms, and collect log data from AWS resources. By continuously monitoring system health and performance, businesses can detect anomalies or failures early and respond proactively to minimize downtime and maintain high availability.
Components of AWS High Availability Architecture

Amazon EC2 (Elastic Compute Cloud):
Amazon EC2 provides resizable compute capacity in the cloud, allowing you to quickly scale capacity up or down as your computing requirements change.
EC2 instances are the virtual servers running in the AWS cloud, offering a variety of instance types optimized for different workloads.
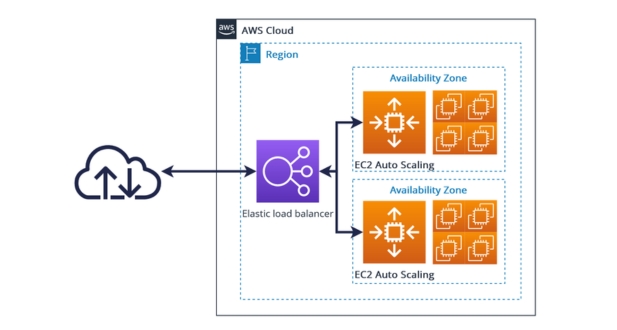
High availability can be achieved by deploying EC2 instances across multiple Availability Zones (AZs), ensuring redundancy and fault tolerance.
Amazon S3 (Simple Storage Service):
Amazon S3 is a scalable object storage service designed to store and retrieve any amount of data from anywhere on the web.
It provides durability by storing data redundantly across multiple facilities and availability zones.
High availability is inherent in S3’s architecture, with its distributed nature and built-in redundancy mechanisms.
Amazon RDS (Relational Database Service):
Amazon RDS is a managed relational database service that makes it easier to set up, operate, and scale a relational database in the cloud.
RDS supports various database engines such as MySQL, PostgreSQL, Oracle, and SQL Server.
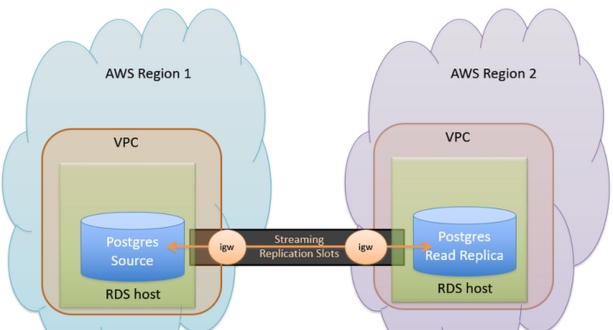
RDS provides features like automated backups, multi-AZ deployments, and read replicas to enhance availability and durability.
Amazon Route 53:
Amazon Route 53 is a highly available and scalable Domain Name System (DNS) web service.
It provides routing policies that enable you to direct traffic based on various factors like geographic location, latency, or health checks.
Route 53’s health checks can automatically route traffic away from failed or unhealthy endpoints, improving application availability.
AWS Auto Scaling:
AWS Auto Scaling helps maintain application availability by automatically adjusting the number of EC2 instances or other resources in response to changing demand.
It allows you to define scaling policies based on metrics like CPU utilization, request count, or custom metrics.
By dynamically scaling resources up or down, Auto Scaling helps ensure that your application can handle varying loads without manual intervention.
AWS ELB (Elastic Load Balancing):
AWS Elastic Load Balancing distributes incoming application or network traffic across multiple targets, such as EC2 instances, containers, or IP addresses.
It helps improve application availability by spreading the load across multiple resources, preventing any single point of failure.
ELB also performs health checks on its registered targets and automatically routes traffic away from unhealthy instances.
Design Patterns for High Availability on AWS
- Multi-AZ Deployment: This pattern involves deploying your application across multiple Availability Zones (AZs) within the same AWS region. An Availability Zone is essentially a distinct data center with independent power, cooling, and networking. By distributing your application across multiple AZs, you ensure redundancy and fault tolerance. If one AZ goes down due to an outage, your application can still continue running in the other AZs.
- Multi-Region Deployment: In addition to deploying across multiple AZs within the same region, you can also deploy your application across multiple AWS regions. This provides geographic redundancy, protecting your application against regional failures or disasters. By spreading your application across different regions, you minimize the risk of downtime caused by a single region outage.
- Active-Active vs. Active-Passive Architectures: These are two different approaches to designing highly available systems. In an active-active architecture, multiple instances of your application are running simultaneously in different locations and are actively serving traffic. This provides high availability and scalability but requires careful coordination to ensure consistency across instances. In contrast, an active-passive architecture involves one primary instance serving traffic while standby instances are ready to take over in case of failure. This approach is simpler to manage but may result in higher latency during failover.
- Blue/Green Deployment: This deployment strategy involves maintaining two identical production environments, referred to as “blue” and “green.” At any given time, one environment serves production traffic while the other remains idle. When it’s time to deploy updates or changes, you switch traffic to the idle environment, allowing you to perform updates without causing downtime for your users. This approach minimizes downtime and allows for easy rollback if issues arise during deployment.
- Disaster Recovery Planning with AWS: Disaster recovery planning involves preparing for and mitigating the impact of catastrophic events on your business operations. AWS provides several services and features to help with disaster recovery planning, including data replication across regions, automated backup and restore mechanisms, and failover solutions such as AWS Site Recovery. By leveraging these tools and implementing best practices, you can ensure that your applications and data remain available and accessible even in the face of unexpected disasters.
Best Practices for Implementing AWS High Availability Architecture
Utilizing AWS’s Managed Services:
AWS offers a wide range of managed services that can help enhance the availability of your architecture. These services, such as Amazon RDS (Relational Database Service), Amazon Aurora, Amazon DynamoDB, and Amazon ElastiCache, are designed to handle common infrastructure tasks, such as database management, caching, and messaging, with built-in high availability features. By leveraging these managed services, you can offload the operational overhead and ensure that your critical components are resilient to failures.
Leveraging AWS Well-Architected Framework:
The AWS Well-Architected Framework provides a set of best practices and guidelines for designing and operating reliable, secure, efficient, and cost-effective systems on AWS. By following the pillars of the Well-Architected Framework – operational excellence, security, reliability, performance efficiency, and cost optimization – you can build a highly available architecture that meets your business requirements while mitigating risks and maximizing performance.
Implementing Infrastructure as Code (IaC):
Infrastructure as Code (IaC) is the practice of managing and provisioning infrastructure through machine-readable definition files, rather than manually configuring resources. By using tools such as AWS CloudFormation or AWS CDK (Cloud Development Kit), you can define your infrastructure in code and automate the deployment process. This enables you to consistently and reliably deploy and update your architecture, reducing the risk of human error and ensuring that your environment is always in a desired state, which is crucial for high availability.
Regular Testing and Simulation of Failures:
High availability is not just about designing for failure, but also about testing your system’s resilience to failures. Regularly conducting failure simulations, such as chaos engineering experiments or disaster recovery drills, can help identify weaknesses in your architecture and ensure that it can withstand various failure scenarios. By proactively testing your system’s resilience, you can uncover vulnerabilities before they impact your users and improve the overall reliability of your architecture.
Monitoring and Alerting:
Early Detection of Issues: Monitoring your AWS environment is essential for detecting and responding to issues before they escalate into full-blown outages. By leveraging AWS CloudWatch, AWS CloudTrail, AWS Config, and other monitoring tools, you can collect and analyze metrics, logs, and events from your infrastructure in real time. Additionally, setting up proactive alerts and notifications can help you quickly identify and remediate potential issues, minimizing downtime and ensuring a high level of availability for your services.
Case Studies and Real-World Examples
Netflix: A Pioneer in AWS High Availability
Netflix, a leading streaming service, has been one of the earliest adopters of AWS. They rely heavily on AWS for their entire infrastructure, from content delivery to customer recommendations. Netflix’s architecture is designed for high availability, ensuring uninterrupted streaming for their millions of subscribers worldwide. They utilize AWS services like Amazon S3 for storage, Amazon EC2 for compute resources, and AWS Lambda for serverless computing to manage their dynamic workload efficiently.
Airbnb: Ensuring 24/7 Availability for Millions of Users
Airbnb, a popular online marketplace for lodging and tourism experiences, operates on AWS to maintain continuous availability for its platform. With millions of users accessing their website and mobile apps globally, Airbnb utilizes AWS services such as Amazon DynamoDB for database management, Amazon CloudFront for content delivery, and Amazon RDS for relational database storage. By leveraging AWS’s infrastructure, Airbnb can scale its resources based on demand, ensuring a seamless experience for hosts and guests.
Lyft: Managing Spikes in Demand with AWS
Lyft, a ride-sharing company, relies on AWS to handle fluctuations in demand and ensure reliable service for its customers. During peak hours or events, Lyft experiences spikes in ride requests, requiring scalable infrastructure to accommodate increased traffic. AWS provides Lyft with the elasticity needed to scale their fleet of servers dynamically. They leverage services like Amazon EC2 Auto Scaling and Amazon RDS to automatically adjust resources based on demand, ensuring that customers can always find a ride when needed.
NASA: High Availability for Critical Space Missions
NASA utilizes AWS to support critical space missions and scientific research projects. With requirements for high availability and fault tolerance, AWS offers NASA the infrastructure needed to store and process vast amounts of data collected from space missions. NASA leverages AWS services like Amazon S3 for data storage, Amazon EC2 for compute resources, and AWS Lambda for serverless computing to analyze mission data efficiently. By leveraging AWS’s global infrastructure, NASA can collaborate with researchers worldwide and ensure the success of their space exploration endeavors.
Challenges and Considerations
Cost Management in High Availability Architectures:
High availability architectures often involve redundant systems, load balancers, failover mechanisms, and other infrastructure components to ensure continuous operation. While these measures are critical for minimizing downtime, they can also significantly increase costs. Managing costs in such architectures requires careful planning and optimization. This may involve evaluating different solutions to find the right balance between cost and reliability, leveraging cloud services for scalability and cost-effectiveness, implementing efficient resource utilization strategies, and regularly reviewing and optimizing infrastructure to ensure cost efficiency over time.
Complexity: Balancing Robustness with Simplicity:
High availability architectures tend to be more complex than traditional setups due to the need for redundancy, failover mechanisms, and other advanced features. However, increased complexity can introduce challenges in terms of system management, troubleshooting, and overall reliability. Balancing robustness with simplicity is crucial to ensure that the architecture remains manageable and maintainable. This may involve adopting modular design principles, automation tools for deployment and management, comprehensive monitoring and alerting systems, and regular testing and validation of the architecture’s resilience.
Security Considerations in High Availability Designs:
Maintaining high availability often requires exposing systems to external networks, increasing the potential attack surface and security risks. Security considerations are paramount in high availability designs to prevent unauthorized access, data breaches, and service disruptions. This includes implementing strong authentication and access control mechanisms, encrypting sensitive data both in transit and at rest, regularly patching and updating software to address security vulnerabilities, conducting regular security audits and penetration testing, and ensuring compliance with relevant regulations and industry standards.
Vendor Lock-in Risks and Mitigation Strategies:
High availability architectures often rely on specialized technologies and services from specific vendors, which can lead to vendor lock-in. Vendor lock-in occurs when a company becomes dependent on a particular vendor’s products or services, making it challenging to switch to alternative solutions in the future. This can pose risks such as limited flexibility, escalating costs, and potential compatibility issues with other systems. Mitigating vendor lock-in risks involves evaluating vendor lock-in potential during the design phase, adopting open standards and interoperable technologies where possible, negotiating flexible contracts with vendors, and maintaining a contingency plan for transitioning to alternative solutions if needed.
Addressing these challenges and considerations requires a comprehensive understanding of the requirements, constraints, and trade-offs involved in designing and managing high-availability architectures. By carefully planning, implementing best practices, and regularly reviewing and optimizing the architecture, organizations can build resilient, cost-effective, and secure systems that meet their availability goals while mitigating potential risks.
Future Trends and Innovations in AWS High Availability
Serverless Computing: Redefining High Availability:
- Serverless computing is revolutionizing the way applications are built and deployed, offering unparalleled scalability and availability. With serverless architectures, developers can focus solely on writing code without worrying about managing servers.
- AWS Lambda is a key service in this domain, allowing developers to run code in response to events without provisioning or managing servers. This inherently enhances high availability as AWS manages the underlying infrastructure, ensuring resilience and fault tolerance.
- The pay-per-use model of serverless computing also enables cost optimization, making it an attractive option for organizations looking to enhance availability without incurring unnecessary infrastructure costs.
Edge Computing and IoT: Distributed Architectures:
- Edge computing brings computation and data storage closer to the sources of data generation, reducing latency and improving performance for IoT applications. AWS offers services like AWS IoT Greengrass, which extends AWS capabilities to edge devices, enabling local execution of code and data storage.
- Distributed architectures in edge computing enhance high availability by decentralizing processing and storage, thereby reducing single points of failure. This enables critical applications to continue functioning even in the event of network disruptions or failures.
- AWS’s global infrastructure allows for seamless integration of edge computing solutions with its cloud services, enabling organizations to build highly available and resilient IoT applications at scale.
AI/ML Integration for Predictive Maintenance:
- AI and machine learning (ML) play a crucial role in predictive maintenance, where algorithms analyze historical data to predict when equipment is likely to fail, allowing for proactive maintenance actions to be taken.
- AWS offers a suite of AI/ML services such as Amazon SageMaker, which provides tools for building, training, and deploying machine learning models at scale. By integrating AI/ML into their infrastructure, organizations can improve asset uptime and availability by predicting and preventing failures before they occur.
- Predictive maintenance not only enhances high availability by minimizing downtime but also reduces maintenance costs and improves operational efficiency.
Quantum Computing: Implications for High Availability:
- Quantum computing represents a paradigm shift in computing power, offering the potential to solve complex problems exponentially faster than classical computers. While still in its early stages, quantum computing has profound implications for high availability.
- Quantum computing can accelerate optimization algorithms used in high availability systems, enabling faster decision-making and more efficient resource allocation.
- AWS is investing in quantum computing through its Amazon Braket service, which allows users to explore, simulate, and run quantum algorithms. As quantum computing matures, it could unlock new possibilities for enhancing high availability through advanced optimization and fault tolerance techniques.
Conclusion:
AWS High Availability Architecture is not just a buzzword; it’s a necessity for businesses operating in today’s digital age. By understanding the principles, components, and best practices outlined in this guide, organizations can build resilient, scalable, and fault-tolerant systems that ensure uninterrupted service delivery to their users. As technology continues to evolve, staying abreast of emerging trends and innovations will be critical for maintaining a competitive edge in the market.
High Availability is crucial for AWS to minimize downtime, ensure uninterrupted service for users, maintain business continuity, and meet service level agreements (SLAs).
Key components include multi-Availability Zone (AZ) deployment, auto-scaling, load balancing, data replication, and use of managed services like Amazon RDS Multi-AZ.
Multi-AZ deployment involves replicating resources across multiple AWS data centers (AZs) within a region, providing redundancy and fault tolerance. In case of failure in one AZ, traffic is automatically routed to healthy AZs.
Auto-scaling dynamically adjusts resources based on demand, ensuring that the system can handle fluctuations in traffic load without degradation in performance or availability.
Load balancers distribute incoming traffic across multiple instances or resources, improving fault tolerance and ensuring that no single component is overwhelmed, thereby enhancing availability.



{kind=link}
{kind=link}
{kind=link}
{kind=link}