
Introduction to AWS Big Data Analytics

Overview of Big Data Analytics
In the contemporary landscape of business operations, the term “big data” has become synonymous with a vast and complex ocean of information. Big data refers to the colossal volume, variety, and velocity of data generated by diverse sources such as social media, sensors, and transactional systems. The essence of big data analytics lies in deciphering patterns, trends, and correlations within this data to extract meaningful insights.
Enterprises, both large and small, grapple with the challenge of harnessing the potential of big data to gain a competitive edge. This is where AWS, Amazon Web Services, emerges as a game-changer. AWS, a cloud computing giant, provides a comprehensive platform for big data analytics, empowering organizations to navigate the intricacies of massive datasets efficiently.
Importance of Big Data Analytics
- Extracting Actionable Insights from Large Datasets:
Big data analytics serves as the gateway to transform raw data into actionable insights. With traditional databases and analysis tools often falling short in handling the sheer volume of contemporary data, AWS offers scalable solutions that enable businesses to process, analyze, and derive valuable insights from large datasets. This transformative capability is crucial for understanding customer behavior, market trends, and operational efficiency.
- Driving Informed Decision-Making and Business Strategies:
The true power of big data lies in its ability to inform decision-making processes. AWS facilitates the integration of analytics into the decision-making fabric of organizations, allowing stakeholders to make informed choices based on empirical evidence. Whether it’s optimizing supply chain management, personalizing customer experiences, or predicting market trends, big data analytics on AWS empowers decision-makers with the knowledge needed to steer their organizations toward success.
In essence, the significance of big data analytics on AWS transcends the realms of technology; it becomes a strategic tool that not only processes data but also shapes the future trajectory of businesses. As we delve deeper into the realms of AWS big data services, we’ll uncover the specific tools and methodologies that make this transformation possible, ushering in a new era of data-driven decision-making.
AWS Big Data Services Overview

Amazon EMR (Elastic MapReduce)
Amazon EMR stands as a cornerstone in AWS’s big data offerings, providing a powerful and flexible solution for processing vast amounts of data. At its core, EMR leverages the capabilities of popular big data frameworks such as Apache Spark, Apache Hadoop, and Apache Hive. This amalgamation of robust frameworks enables organizations to effortlessly process and analyze data at scale.
- Overview of EMR:
Amazon EMR simplifies the deployment and management of big data frameworks, facilitating the processing of vast datasets using distributed computing paradigms. It allows users to launch clusters with the required configuration, dynamically scale resources based on workload, and leverage the parallel processing capabilities of frameworks like Apache Spark for efficient data processing.
- Integration with Popular Big Data Frameworks:
EMR’s compatibility with Apache Spark and Hadoop makes it a versatile choice for organizations with diverse data processing needs. Apache Spark, known for its in-memory processing capabilities, enhances the speed and efficiency of data analysis, while Hadoop provides a robust ecosystem for distributed storage and processing. EMR’s seamless integration with these frameworks empowers users to choose the tools that best suit their analytical requirements.
Amazon Redshift
Amazon Redshift is AWS’s fully managed data warehousing service designed for high-performance analytics. It stands out as a pivotal player in the big data landscape, offering organizations the ability to efficiently store and analyze large volumes of data.
- Introduction to Redshift:
Redshift is purpose-built for data warehousing, providing a scalable and cost-effective solution for managing analytical workloads. It enables organizations to run complex queries on massive datasets with high performance, making it a preferred choice for businesses seeking to derive insights from their data.
- Scaling and Optimizing Performance:
Scalability is a key feature of Redshift, allowing users to easily scale their data warehouse as their analytical needs grow. The ability to add or remove nodes ensures that performance remains optimal, even as the volume of data increases. Redshift also offers features like automated backups and continuous monitoring, contributing to its efficiency and reliability.
Amazon Kinesis
Amazon Kinesis is AWS’s answer to real-time data streaming and analytics. In a world where data is generated at an unprecedented pace, Kinesis provides organizations with the tools to ingest, process, and analyze streaming data in real-time.
- Real-Time Data Streaming and Analytics Capabilities:
Kinesis offers a suite of services, including Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics, each catering to different aspects of real-time data processing. Kinesis Data Streams enables the ingestion of large amounts of data in real-time, while Kinesis Data Analytics allows for real-time analysis of streaming data, extracting meaningful insights.
- Use Cases for Kinesis:
The applications of Kinesis span various industries and scenarios. From real-time analytics in e-commerce to monitoring and anomaly detection in IoT devices, Kinesis empowers organizations to respond rapidly to emerging patterns in their data. Its seamless integration with other AWS services further enhances its versatility.
As we navigate through the multifaceted landscape of AWS big data services, each offering plays a distinct role in enabling organizations to harness the power of their data for strategic decision-making and innovation.
Building Data Pipelines on AWS

- Amazon Glue
Amazon Glue stands as a pivotal service in AWS’s arsenal, offering robust capabilities for building and managing ETL (Extract, Transform, Load) processes. It plays a crucial role in automating data preparation and integration, streamlining the path from raw data to actionable insights.
- ETL Processes with Glue:
At the heart of Glue lies its ability to simplify ETL processes. It allows users to define data sources, apply transformations, and seamlessly load the processed data into target destinations. The visual interface of Glue DataBrew further facilitates the exploration and transformation of data, enabling users to prepare their datasets for analysis without the need for extensive coding.
- Automated Data Preparation and Integration:
Glue’s strength lies in its automation capabilities. By automatically discovering and cataloging metadata about datasets, Glue eliminates the manual effort involved in data preparation. It then orchestrates the integration of diverse datasets, ensuring that data is ready for analysis. This level of automation not only accelerates the ETL process but also enhances accuracy and consistency.
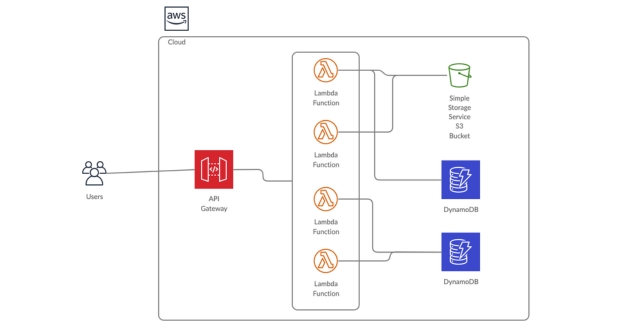
AWS Lambda for Serverless Data Processing
AWS Lambda, a key player in AWS’s serverless computing paradigm, transforms the landscape of data processing by offering a serverless approach to executing code. Its integration into big data workflows brings forth a range of benefits, making it a valuable asset in the data processing toolkit.
- Leveraging Serverless Architecture for Data Processing:
Lambda allows organizations to embrace a serverless architecture, where code is executed on-demand without the need for provisioning or managing servers. In the context of big data, Lambda enables the execution of code snippets in response to events, making it an ideal choice for processing data in real-time or on a scheduled basis.
- Use Cases and Benefits of Lambda in Big Data Workflows:
Lambda finds application in various big data scenarios. Whether it’s transforming and enriching data before storage, processing real-time streaming data, or executing periodic batch jobs, Lambda provides a flexible and scalable solution. Its pay-as-you-go pricing model ensures cost-effectiveness, especially for sporadic or unpredictable workloads.
Amazon Data Pipeline
Amazon Data Pipeline serves as the orchestration powerhouse, allowing organizations to automate and coordinate complex data workflows seamlessly. By integrating multiple AWS services, Data Pipeline simplifies the management of data movement, ensuring a smooth and efficient journey across various stages of the data lifecycle.
- Orchestrating and Automating Data Workflows:
Data Pipeline enables users to define, schedule, and manage data-driven workflows. It acts as the conductor, orchestrating the execution of tasks across different AWS services in a logical sequence. This automation not only enhances operational efficiency but also reduces the risk of errors associated with manual intervention.
- Integrating Multiple AWS Services for Seamless Data Movement:
The strength of Data Pipeline lies in its ability to integrate with a plethora of AWS services. From extracting data from Amazon S3 to transforming it with EMR clusters and loading it into Redshift for analysis, Data Pipeline streamlines the end-to-end data movement process. This integration ensures that each step in the pipeline seamlessly transitions into the next, creating a cohesive and efficient workflow.
As organizations navigate the intricate landscape of big data analytics on AWS, the combination of Glue, Lambda, and Data Pipeline empowers them to construct robust data pipelines that drive efficiency, scalability, and agility in their analytics endeavors.
Data Storage Solutions on AWS
Amazon S3 for Data Storage
Amazon S3, or Simple Storage Service, stands tall as a cornerstone in AWS’s data storage solutions. Renowned for its scalability, cost-effectiveness, and versatility, S3 serves as the go-to choice for organizations dealing with vast amounts of data.
- Scalable and Cost-Effective Object Storage:
S3 provides a scalable object storage solution, allowing users to store and retrieve virtually any amount of data. Its flat, simple structure enables easy organization, while its pay-as-you-go pricing ensures cost-effectiveness. Organizations benefit from S3’s ability to seamlessly scale with their growing data needs without incurring upfront costs for provisioning.
- Best Practices for Organizing and Managing Data in S3:
Effectively organizing data in S3 is crucial for optimizing storage and retrieval. Best practices include employing meaningful naming conventions for buckets and objects, utilizing folders for logical organization, and implementing versioning and lifecycle policies. These practices not only enhance data management but also contribute to efficient analytics workflows.
Amazon DynamoDB
In the realm of NoSQL databases, Amazon DynamoDB takes the spotlight, offering real-time access to large datasets. Its high performance, low-latency, and seamless scalability make it an ideal choice for scenarios demanding quick and efficient data retrieval.
- NoSQL Database for Real-Time Access to Large Datasets:
DynamoDB’s NoSQL nature allows for flexible and fast retrieval of data. Its ability to handle large datasets with low-latency access makes it suitable for applications requiring real-time responsiveness. The database’s seamless scalability ensures that it can accommodate varying workloads, providing a reliable foundation for big data scenarios.
- Use Cases and Considerations for Using DynamoDB in Big Data Scenarios:
DynamoDB finds its application in various big data scenarios, from real-time analytics to supporting applications with dynamic and rapidly changing datasets. Considerations include designing optimal table schemas, leveraging secondary indexes for efficient queries, and utilizing features like DynamoDB Streams for real-time data processing.
AWS Glue DataBrew
Data preparation is a pivotal step in the big data analytics process, and AWS Glue DataBrew emerges as a powerful tool for simplifying this intricate task. With its visual tools, DataBrew empowers users to clean and transform data without the need for extensive coding.
- Data Preparation and Cleaning with Visual Tools:
DataBrew’s visual interface allows users to visually explore, clean, and transform their data. The tool automates the process of identifying data patterns, suggesting transformations, and visually representing the impact of applied changes. This approach democratizes data preparation, enabling a broader set of users to participate in the analytics process.
- Simplifying Data Transformation Tasks for Analytics:
DataBrew integrates seamlessly with other AWS services, making it an integral part of the analytics workflow. By simplifying data transformation tasks, it accelerates the preparation phase, allowing organizations to focus more on deriving insights from their data. DataBrew supports a variety of data formats and sources, ensuring compatibility with diverse datasets.
Advanced Analytics and Machine Learning
Amazon SageMaker
Amazon SageMaker stands as a beacon in the realm of machine learning on AWS, empowering users to seamlessly build, train, and deploy machine learning models. In the context of big data analytics, SageMaker plays a pivotal role in integrating advanced analytics and predictive capabilities.
- Building and Deploying Machine Learning Models:
SageMaker simplifies the end-to-end machine learning process, offering a collaborative environment for data scientists and developers. From data exploration to model deployment, SageMaker streamlines tasks such as data labeling, algorithm selection, and hyperparameter tuning. Its scalable infrastructure ensures efficient model training on large datasets, a fundamental requirement in big data analytics.
- Integration with Big Data for Predictive Analytics:
When it comes to big data analytics, SageMaker seamlessly integrates with other AWS big data services, allowing users to derive predictive insights from massive datasets. The synergy between SageMaker and services like Amazon S3 and AWS Glue enables the creation of robust predictive analytics pipelines. This integration ensures that machine learning models can leverage the full spectrum of available data for accurate predictions.
Amazon QuickSight
In the realm of business intelligence and data visualization, Amazon QuickSight takes center stage. As organizations delve into big data analytics, QuickSight emerges as a powerful tool for creating interactive dashboards and gaining valuable insights from large datasets.
- Business Intelligence and Visualization Tools:
QuickSight provides a user-friendly interface for creating insightful visualizations without the need for extensive coding. Its drag-and-drop functionality allows users to explore and analyze data intuitively. The tool supports a variety of data sources, including those stored in Amazon S3 and Amazon Redshift, making it a versatile solution for big data scenarios.
- Creating Interactive Dashboards for Data Exploration:
For big data analytics to be truly impactful, data exploration is paramount. QuickSight enables the creation of interactive dashboards that facilitate dynamic data exploration. Users can drill down into specific data points, apply filters, and uncover hidden patterns, empowering them to make data-driven decisions effectively.
Use Cases for Advanced Analytics
To contextualize the capabilities of advanced analytics in big data scenarios, exploring industry-specific use cases provides valuable insights.
- Industry-Specific Examples of Leveraging Big Data for Advanced Analytics:
In healthcare, advanced analytics can be applied to vast datasets to enhance patient outcomes through predictive diagnostics. Retailers can leverage big data analytics and machine learning for demand forecasting and personalized customer experiences. Financial institutions can use advanced analytics to detect fraudulent activities within extensive transaction datasets.
- Benefits and Insights Gained from Combining Big Data and Machine Learning:
The amalgamation of big data and machine learning unlocks a plethora of benefits. Organizations can gain predictive insights, identify patterns, and optimize decision-making processes. The synergy between large datasets and advanced analytics not only improves operational efficiency but also opens doors to innovation and competitive advantage.
Security and Compliance in AWS Big Data Analytics
Data Encryption and Access Control
Ensuring the security and privacy of data is paramount in the realm of big data analytics on AWS. Robust measures are in place to safeguard sensitive information and control access to datasets effectively.
- Ensuring Data Security and Privacy in Big Data Analytics:
In the context of AWS big data analytics, data encryption serves as a foundational pillar for securing information. Amazon S3, a key storage solution in big data projects, supports server-side encryption, protecting data at rest. Additionally, encryption in transit is facilitated through secure communication protocols. This two-pronged approach ensures that data remains confidential and integral throughout its lifecycle.
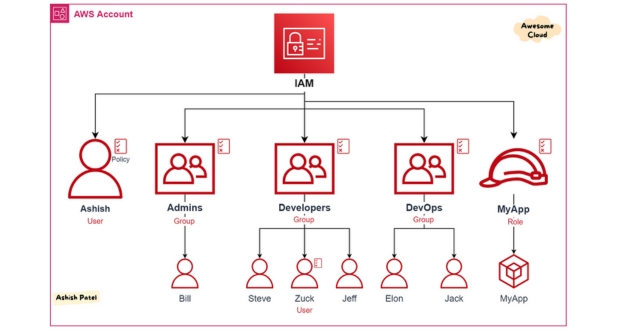
- IAM (Identity and Access Management) Best Practices:
IAM plays a pivotal role in controlling access to AWS resources. In the context of big data analytics, adhering to IAM best practices is crucial. Implementing the principle of least privilege ensures that users and processes have only the permissions necessary for their specific tasks. Granular control over access, coupled with regular audits, strengthens the security posture of big data projects.
Compliance Standards
Adhering to regulatory requirements is a cornerstone in the landscape of big data projects. AWS, as a cloud service provider, has obtained numerous compliance certifications, providing assurances to organizations embarking on big data analytics endeavors.
- Adhering to Regulatory Requirements in Big Data Projects:
Different industries are subject to specific regulations governing data handling and privacy. In the healthcare sector, for instance, the Health Insurance Portability and Accountability Act (HIPAA) sets stringent standards for the protection of patient data. AWS ensures that its big data services comply with such regulations, enabling organizations to leverage analytics while meeting their industry-specific compliance needs.
- AWS Compliance Certifications and Assurances:
AWS has undergone rigorous assessments to obtain certifications that validate its commitment to security and compliance. Examples include ISO 27001 for information security management and SOC 2 for controls relevant to security, availability, and confidentiality. These certifications instill confidence in organizations utilizing AWS for big data analytics, assuring them that the platform aligns with industry standards.
Performance Optimization and Cost Management
Scaling and Performance Tuning
Optimizing the performance of big data processing on AWS involves strategic scaling and fine-tuning to ensure efficient resource utilization.
- Strategies for Optimizing Performance in Big Data Processing:
Effective scaling strategies play a crucial role in optimizing big data analytics performance. AWS offers auto-scaling capabilities, allowing resources to dynamically adjust based on the workload. By configuring auto-scaling policies, organizations can ensure that the infrastructure scales up during peak demand and scales down during periods of lower activity. Additionally, fine-tuning parameters such as memory allocation and parallelism in data processing frameworks like Apache Spark contributes to achieving optimal performance.
- Auto-scaling and Resource Management:
Auto-scaling is a key feature that enables automatic adjustments to the number of compute resources based on the workload. Leveraging auto-scaling groups, organizations can set policies to dynamically scale instances in and out. This ensures that the infrastructure aligns with the demands of big data processing, providing optimal performance without unnecessary resource allocation.
Cost-Efficient Big Data Solutions
Effective cost management is integral to the success of big data projects on AWS. Understanding the pricing models for various services and implementing cost optimization strategies is essential.
- Understanding AWS Pricing Models for Big Data Services:
AWS provides a flexible pricing model for its big data services, offering options like on-demand pricing, reserved instances, and spot instances. Organizations should carefully analyze their usage patterns and select the pricing model that aligns with their specific needs. This understanding enables them to optimize costs while ensuring access to the necessary resources.
- Cost Optimization Strategies for Managing Analytics Expenses:
Implementing cost optimization strategies is crucial for organizations looking to manage their analytics expenses efficiently. This involves leveraging reserved instances for predictable workloads, utilizing spot instances for cost-effective computing, and employing resource tagging for accurate cost allocation. Regular monitoring and adjusting the infrastructure based on actual usage contribute to maintaining a cost-efficient big data analytics environment.
Case Studies: Successful Implementations of AWS Big Data Analytics
Real-World Examples
Examining real-world examples of organizations successfully implementing AWS big data analytics provides valuable insights into the practical applications and benefits of the platform.
AWS has been instrumental in transforming businesses across various industries, allowing them to harness the power of big data for actionable insights. Case studies highlight organizations that have effectively utilized AWS services, such as Amazon EMR, Redshift, and SageMaker, to derive meaningful conclusions from their vast datasets.
Lessons Learned and Best Practices from Case Studies:
Analyzing these case studies not only offers inspiration but also imparts crucial lessons and best practices. Organizations can learn from the challenges faced, the strategies employed, and the outcomes achieved by their peers. Insights into optimizing data pipelines, overcoming scalability issues, and implementing advanced analytics provide a practical guide for others embarking on similar big data journeys.
By delving into these real-world examples, businesses can glean valuable knowledge to enhance their own AWS big data analytics initiatives.
Future Trends in AWS Big Data Analytics
Emerging Technologies
The landscape of big data analytics is dynamic, with constant advancements shaping its future. AWS is at the forefront of embracing emerging technologies that will redefine how organizations process and derive insights from massive datasets.
As we move forward, there is a keen focus on integrating cutting-edge technologies into the AWS big data ecosystem. Exploring trends such as artificial intelligence, machine learning, and real-time analytics promises to unlock new dimensions of data processing efficiency and accuracy. Innovations like serverless computing, enhanced data visualization tools, and improved automation are poised to reshape the way businesses leverage big data on AWS.
Predictions for the Evolution of AWS Big Data Services:
Looking ahead, predictions for the evolution of AWS big data services include enhanced scalability, more streamlined data integration tools, and increased focus on real-time analytics. The continued commitment to security, compliance, and cost-effectiveness is expected to be central to AWS’s strategy.
By staying abreast of these emerging trends, businesses can position themselves to harness the full potential of AWS big data analytics in the ever-evolving technological landscape.
Conclusion: Harnessing the Power of AWS Big Data Analytics
In conclusion, AWS has revolutionized the landscape of big data analytics, providing organizations with a robust and scalable platform to extract valuable insights from vast datasets. The comprehensive suite of AWS big data services, ranging from Amazon EMR and Redshift to SageMaker and QuickSight, empowers businesses to process, analyze, and visualize data with unparalleled efficiency.
By seamlessly integrating emerging technologies and fostering a commitment to security and compliance, AWS ensures that businesses can navigate the complexities of big data analytics with confidence. The success stories highlighted in case studies underscore the transformative impact AWS has had on diverse industries.
As we peer into the future, the anticipated trends in AWS big data analytics promise even greater capabilities. From the integration of artificial intelligence to advancements in real-time analytics, AWS remains at the forefront of innovation.
In harnessing the power of AWS big data analytics, organizations not only gain actionable insights but also unlock the potential for innovation, competitive advantage, and strategic decision-making. The journey with AWS in the realm of big data analytics is a dynamic one, marked by continual advancements and the promise of unparalleled possibilities.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}